분산 환경을 위한 그룹 기대 정책 최적화
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
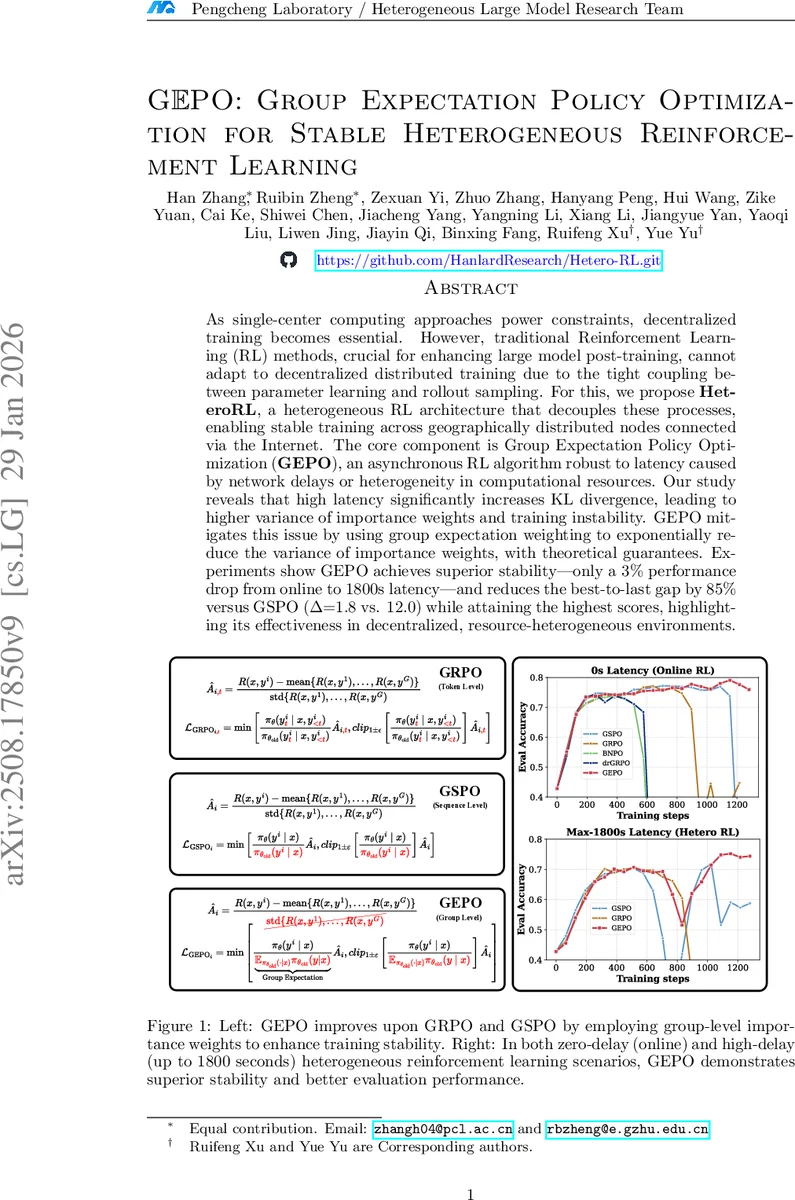
본 논문은 지연과 연산 자원 이질성이 큰 인터넷 기반 분산 학습 환경에서 강화학습(RL)의 안정성을 확보하기 위해 HeteroRL이라는 비동기 아키텍처와, 그룹 수준에서 중요도 가중치를 재구성하는 GEPO 알고리즘을 제안한다. GEPO는 KL 발산이 크게 증가하는 상황에서도 중요도 가중치의 분산을 지수적으로 감소시켜, 1800초 지연에서도 성능 저하를 3% 수준으로 억제한다.
상세 분석
GEPO는 기존 토큰‑레벨 중요도 가중치(p·q) 방식에서 발생하는 고분산 문제를 근본적으로 해결한다. 논문은 먼저 정책 πθ가 샘플러와 학습기 사이에 τ 만큼의 스테일리티(staleness)를 갖는 상황을 수식화하고, L(θ)=E_{x∼D, y∼πθ_k}
댓글 및 학술 토론
Loading comments...
의견 남기기