FLARE: 강화학습 기반 케이블 매달린 탑재물 쿼드로터의 민첩 비행
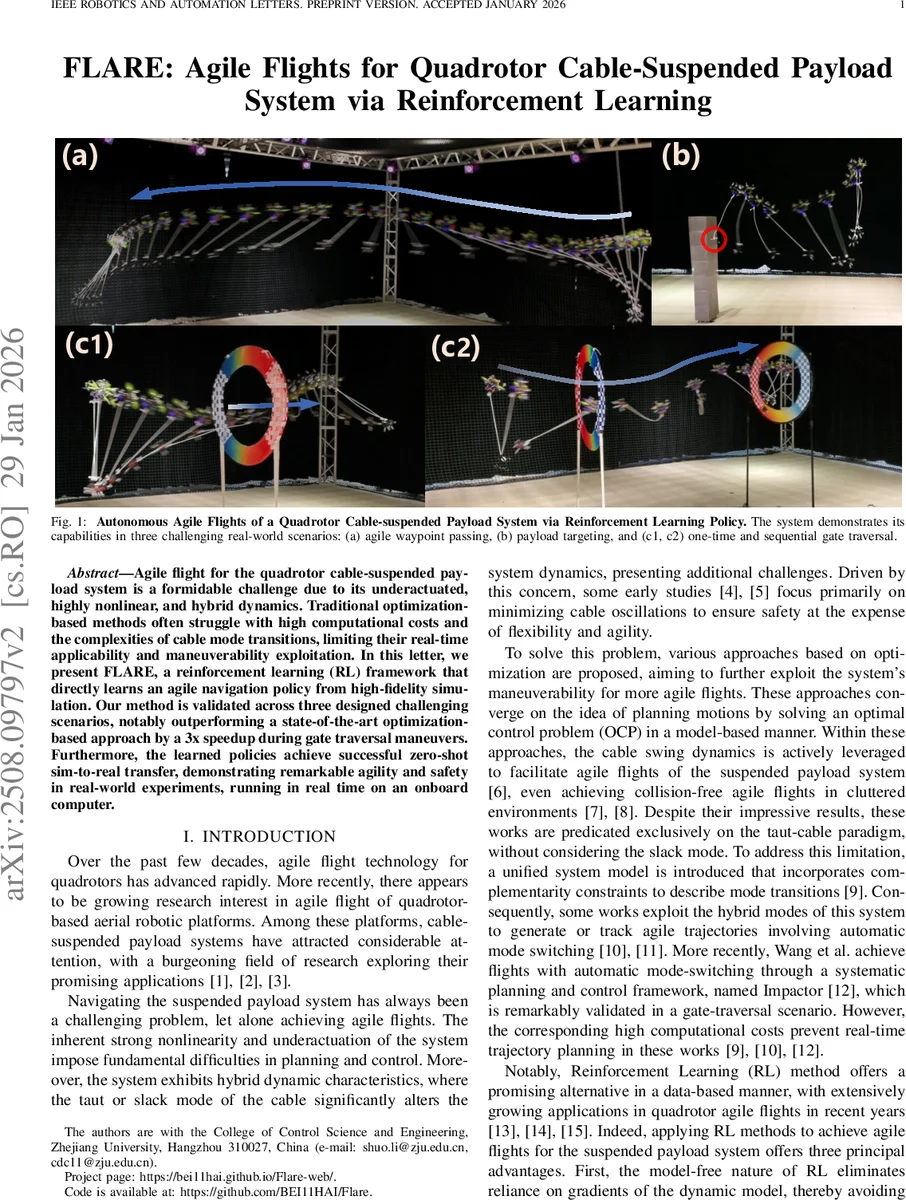
초록
본 논문은 고충실도 시뮬레이터에서 강화학습(PPO)으로 훈련된 정책을 통해, 케이블이 장착된 탑재물을 운반하는 쿼드로터가 복합적인 슬랙·타이트 모드 전이를 실시간으로 처리하며, 게이트 통과, 웨이포인트 통과, 탑재물 목표 도달 등 세 가지 고난이도 시나리오에서 기존 최적화 기반 방법보다 3배 빠른 비행을 구현하고, 온보드 컴퓨터에서 실시간 실행 및 제로샷 시뮬‑투‑리얼 전이까지 달성함을 보여준다.
상세 분석
FLARE는 케이블‑서스펜디드 페이로드 시스템의 핵심 난제인 ‘하이브리드(슬랙/타이트) 동역학’과 ‘비선형·언더액추에이션’ 특성을 모델‑프리 강화학습으로 직접 다룬다. 저자는 시스템 상태를 쿼드로터 12차원(속도·회전 행렬)과 페이로드 편향각 2차원으로 정의하고, 이를 일반 관측(o_general)으로 통합한다. 시나리오별 특화 관측(o_specific)과 보상(r_specific)을 추가함으로써, 정책이 목표 진행도(거리 감소), 안전(편향각 제한), 충돌(작업공간 위반), 부드러움(액션 변화 억제) 등을 동시에 최적화하도록 설계했다. 특히, r_safe는 페이로드 각도가 사전 정의된 임계값을 초과하면 페널티를 부여해 프로펠러와의 충돌 위험을 사전에 차단한다. 보상 가중치 λ1~λ3은 각각 부드러움, 시나리오 목표, 게이트 접근을 조정해 학습 안정성을 확보한다.
훈련은 Genesis GPU‑벡터화 시뮬레이터에서 0.01 s 타임스텝으로 진행되며, PPO 기반 MLP(2×128) 정책이 0.452.42 시간(총 102252 M 타임스텝) 안에 수렴한다. 이는 전통적인 최적화(OCP) 방식이 요구하는 수십 초~수 분 수준의 계산량과 비교해 획기적인 속도 향상이다. 또한, 도메인 랜덤라이제이션(초기 편향각 ±10° 변동)과 목표·게이트 위치의 무작위 샘플링을 통해 시뮬‑투‑리얼 격차를 최소화하고, 실제 비행에서 제로샷 전이를 성공시켰다.
실험 결과는 세 시나리오 모두에서 기존 최적화 기반 ‘Impaactor’ 대비 3배 빠른 통과 시간을 기록했으며, 온보드(예: Raspberry Pi 4)에서 200 Hz 이상의 실시간 추론이 가능함을 입증한다. 이는 강화학습이 복합 하이브리드 시스템의 실시간 제어에 충분히 적용 가능함을 증명하는 중요한 사례이며, 향후 복잡한 다중 로봇·다중 페이로드 환경에도 확장될 여지를 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기