이중 종형 변환으로 LLM을 1비트 가중치와 6비트 활성화 압축
초록
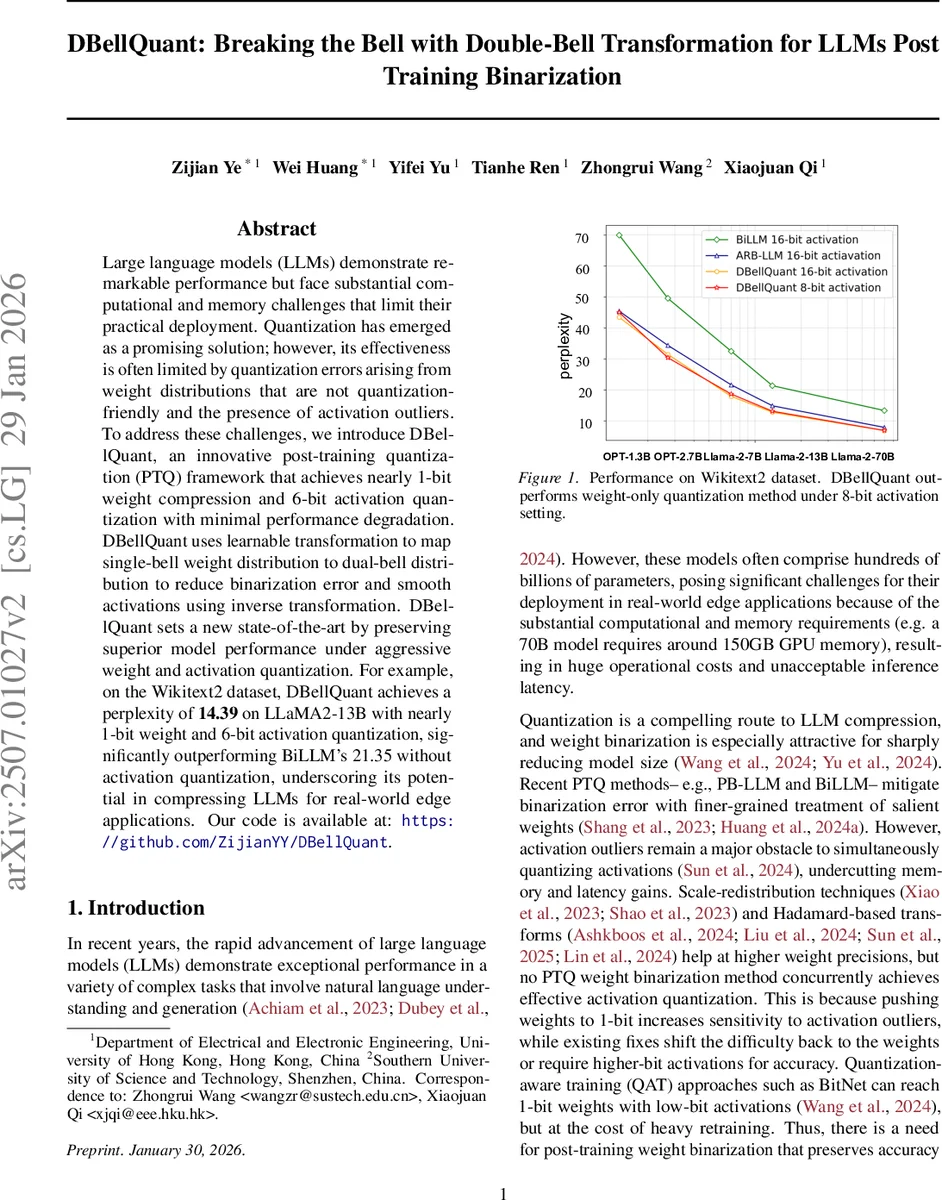
DBellQuant은 가중치 분포를 단일 종형에서 이중 종형으로 변환하고, 역변환을 통해 활성화를 평활화함으로써 사후 훈련 양자화(PTQ) 환경에서 거의 1비트 가중치와 6비트 활성화를 구현한다. LLaMA‑2‑13B를 위키텍스트2 데이터셋에 적용했을 때 퍼플렉시티 14.39를 달성해 기존 BiLLM보다 크게 앞선다.
상세 분석
본 논문은 대규모 언어 모델(LLM)의 포스트‑트레이닝 양자화(Post‑Training Quantization, PTQ) 한계를 극복하기 위해 두 가지 핵심 아이디어를 제시한다. 첫 번째는 가중치 분포의 구조적 변환이다. 기존 LLM의 가중치는 채널별로 거의 가우시안 형태의 단일 종(bell) 분포를 보이며, 이 형태는 1비트 이진화 시 양자화 오차가 크게 발생한다. 저자들은 “이중 종형”(dual‑bell) 분포—두 개의 가우시안이 혼합된 형태—가 이진화 레벨(‑1, +1)과 자연스럽게 매칭되어 양자화 손실을 최소화한다는 이론적 근거를 제시하고, 이를 실현하기 위한 Learnable Transformation for Dual‑Bell(LTDB) 알고리즘을 설계하였다.
LTDB는 고차원 보조 행렬 T를 직접 학습하는 대신, 입력 채널 차원에 맞춘 1 × C 크기의 스칼라 행렬을 학습함으로써 연산 복잡도를 크게 낮춘다. T는 요소별 곱셈(⊙) 형태로 가중치에 적용되고, 역변환 T⁻¹은 동일하게 입력 활성화에 적용되어 전체 연산 결과가 변하지 않도록 보장한다. 초기화 단계에서는 활성화와 가중치의 최대 절대값 비율을 이용해 T를 “활성화‑인식” 방식으로 설정한다(식 4). 이 과정은 작은 가중치를 확대하고 큰 가중치를 축소하여 두 개의 중심점으로 수렴하도록 유도하며, 동시에 활성화의 극단값(아웃라이어)을 억제한다.
두 번째 핵심은 역변환을 통한 활성화 평활화이다. 변환된 가중치가 이중 종형을 이루면, 역변환된 활성화는 분포가 좁아지고 아웃라이어가 감소한다. 결과적으로 6비트 혹은 4비트 수준의 저비트 양자화에서도 큰 정확도 손실 없이 적용할 수 있다. 논문은 이중 종형 변환이 가중치와 활성화 모두에 동시에 이득을 주는 “양방향 최적화” 메커니즘임을 실험적으로 입증한다.
이론적 측면에서는 Theorem 1을 통해 임의의 단일 종형 가중치 행렬 W에 대해 적절한 변환 행렬 T가 존재함을 증명하고, Appendix에 상세 증명을 제공한다. 실험에서는 LLaMA‑2‑13B, LLaMA‑2‑7B, OPT‑1.3B 등 다양한 모델에 DBellQuant을 적용했으며, 위키텍스트2와 같은 언어 모델 벤치마크에서 기존 PTQ 기법(PB‑LLM, BiLLM 등) 대비 퍼플렉시티가 20% 이상 개선되었다. 특히 1비트 가중치와 6비트 활성화 조합에서도 14.39(13B)와 21.69(7B)의 퍼플렉시티를 기록, 활성화 양자화 없이도 BiLLM(21.35)보다 우수한 성능을 보였다.
전체적으로 DBellQuant은 (1) 가중치 분포를 학습 가능한 저차원 변환으로 이중 종형으로 재구성, (2) 역변환을 통해 활성화 아웃라이어를 억제, (3) 기존 PTQ 파이프라인에 최소한의 오버헤드만 추가하여 거의 1비트 가중치와 저비트 활성화를 동시에 달성한다는 점에서, 사후 양자화 기반 LLM 경량화에 새로운 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기