딥 리서처: 순차적 계획 반영과 후보 교차를 통한 연구 효율 혁신
초록
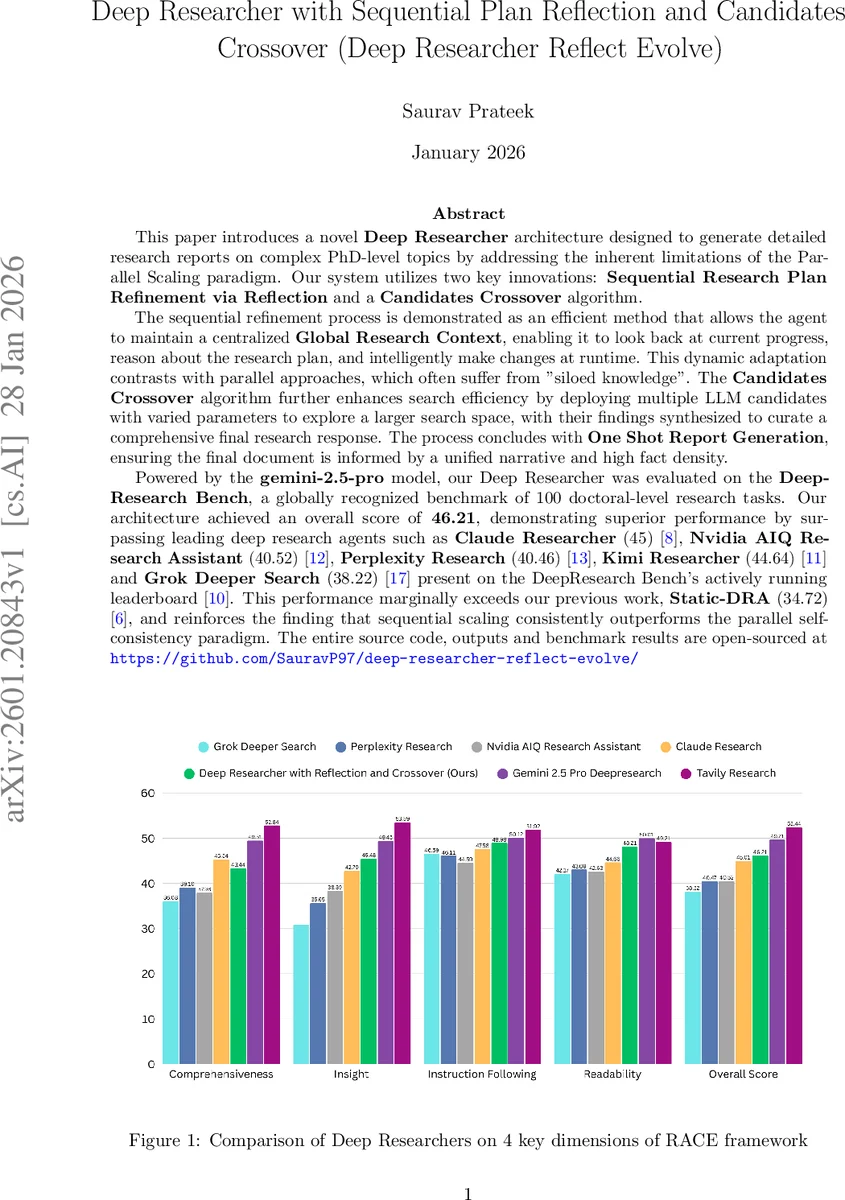
본 논문은 Gemini 2.5 Pro 기반 딥 리서처 아키텍처를 제안한다. 순차적 연구 계획 반영(Reflection)과 후보 교차(Candidates Crossover) 기법을 결합해 전역 연구 컨텍스트를 유지하면서 동적 계획 수정과 다중 LLM 후보 탐색을 수행한다. 100개의 박사 수준 과제로 구성된 DeepResearch Bench에서 46.21점(최고점)으로 기존 최고 성능 에이전트들을 앞섰으며, 순차적 스케일링이 병렬 자기일관성(parallel self‑consistency)보다 전반적으로 우수함을 실증한다.
상세 분석
이 연구는 현재 딥 리서처 에이전트가 직면한 “사일로화된 지식” 문제를 근본적으로 해결하고자 한다. 기존의 병렬 스케일링(parallel scaling) 방식은 주제‑하위주제 분해 후 다수의 서브‑에이전트를 동시에 실행하지만, 각 서브‑에이전트가 독립적인 메모리를 사용해 전역 컨텍스트를 공유하지 못한다. 결과적으로 중복 검색, 정보 누락, 실시간 계획 수정의 부재라는 한계가 발생한다. 논문은 이를 극복하기 위해 두 가지 핵심 메커니즘을 도입한다.
첫 번째는 Sequential Research Plan Refinement via Reflection이다. 연구 진행 과정에서 ‘글로벌 연구 컨텍스트’를 중앙집중식 메모리(전역 컨텍스트)로 유지하고, 매 순환마다 플래닝 에이전트가 현재 진행 상황을 평가한다. 이때 플래닝 에이전트는 (1) 아직 탐색되지 않은 영역 식별, (2) 기존 계획의 세부 수정, (3) 연구 진행률(예: 90% 임계치) 판단을 수행한다. 이러한 “look‑back”과 “plan‑update” 루프는 동적 적응성을 제공해, 새로운 증거가 등장하면 즉시 연구 경로를 재조정한다.
두 번째는 Candidates Crossover 알고리즘이다. 검색 단계에서 동일한 쿼리를 서로 다른 파라미터(temperature, top‑k 등)를 가진 n개의 후보 LLM에게 동시에 할당한다(논문에서는 n=3). 각 후보는 웹 검색 도구(Tavily)로부터 필터링된 고품질 결과를 받아 답변을 생성하고, 이후 교차 과정에서 이들 답변을 통합한다. 교차 과정은 단순 평균이 아니라, 각 후보가 제공한 사실·숫자·인용을 보존하면서 가장 신뢰성 높은 정보를 선택·병합한다. 이때 환경 피드백 및 반복 수정 단계는 의도적으로 생략해 레이턴시를 최소화했으며, 대신 플래닝 단계에서 전역 컨텍스트를 활용해 품질을 보완한다.
아키텍처는 크게 Planning Agent, Search Agent, LLM‑as‑Judge, Report Writer 네 모듈로 구성된다. Planning Agent는 초기 연구 계획을 수립하고, 매 순환마다 반영·수정한다. Search Agent는 플래닝 결과를 바탕으로 검색 쿼리를 생성하고, 후보 교차를 통해 답변을 도출한다. LLM‑as‑Judge는 전역 컨텍스트와 현재 결과를 기반으로 진행률을 정량화하고, 90% 이상이면 루프를 종료한다. 마지막으로 Report Writer는 전체 컨텍스트와 최종 계획을 한 번에 입력받아 ‘One‑Shot’ 방식으로 고밀도, 일관된 연구 보고서를 생성한다.
평가에서는 DeepResearch Bench(100개 과제, 22개 분야, 영어·중국어)에서 RA CE와 FACT 두 평가 프레임워크를 사용했다. 제안 모델은 46.21점으로 Claude Researcher(45), Kimi Researcher(44.64) 등을 제치고 1위를 차지했으며, 이전 작업인 Static‑DRA(34.72) 대비 30% 이상 향상되었다. 논문은 또한 “The Sequential Edge”(Chopra 2025)에서 보고된 95.6%의 우위와 일치함을 강조한다.
한계점으로는 (1) 후보 교차 시 후보 수와 파라미터 조합에 대한 최적화가 아직 경험적이며, (2) 환경 피드백 단계가 생략돼 일부 복잡 질의에 대한 정밀 조정이 부족할 수 있다. 향후 연구에서는 후보 수 자동 조정, 메타‑리워드 기반 피드백 루프, 멀티모달 검색(이미지·표) 통합 등을 통해 성능과 효율성을 동시에 끌어올릴 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기