확장된 NPU 설계로 구현하는 효율적인 Diffusion LLM 샘플링
초록
Diffusion 기반 대형 언어 모델(dLLM)의 샘플링 단계가 GPU에서 전체 추론 지연의 70%까지 차지한다는 사실을 발견하고, 기존 GEMM 중심 NPU가 처리하기 어려운 대규모 vocab 로짓, reduction·top‑k 선택, 마스크 업데이트 등을 전용 비‑GEMM 벡터 명령어와 혼합 정밀도 메모리 계층으로 최적화한 d‑PLENA 아키텍처를 제안한다. 시뮬레이션·RTL 검증 결과, 동등 공정에서 RTX A6000 대비 최대 2.53배 가속을 달성하였다.
상세 분석
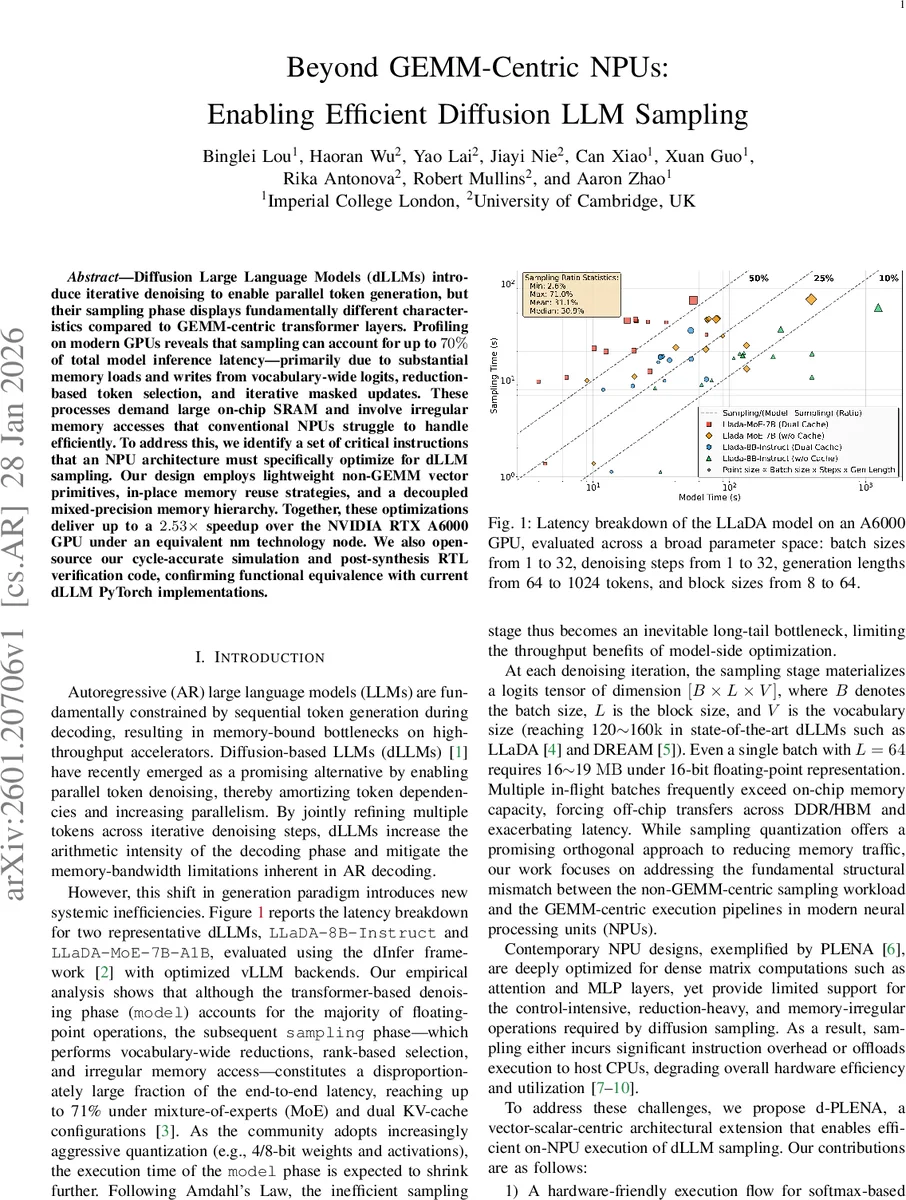
본 논문은 Diffusion Large Language Model(dLLM)의 샘플링 단계가 전통적인 GEMM‑centric NPU 설계와 근본적으로 맞지 않음을 실증적으로 보여준다. GPU 프로파일링 결과, vocab‑size가 120 k~160 k에 달하는 최신 dLLM에서는 매 디노이징 스텝마다 B × L × V 형태의 로짓 텐서가 생성되며, 이를 전체 토큰에 대해 softmax·argmax·top‑k 연산에 사용한다. 이러한 연산은 대용량 메모리 로드·스토어와 불규칙한 인덱스 접근을 동반해 메모리 대역폭과 SRAM 용량을 급격히 소모하고, 전체 추론 지연의 70%까지 차지한다. 기존 NPU는 고밀도 GEMM(Attention, MLP) 최적화에 초점을 맞추어 reduction·selection·masked‑update와 같은 제어‑중심 연산을 지원하는 전용 명령어가 부족하다. 논문은 이를 해결하기 위해 네 가지 핵심 설계를 제시한다. 첫째, Softmax를 Stable‑Max 형태로 변형해 max·exp‑sum을 단일 reduction 유닛에서 수행하고, 중간 결과를 제자리(in‑place)로 덮어써 SRAM 활용도를 극대화한다. 둘째, V_RED_MAX_IDX, V_TOPK_MASK, V_SELECT_INT 등 비‑GEMM 벡터 프리미티브를 ISA에 추가해 argmax·top‑k·masked‑select를 한 사이클 내에 처리한다. 셋째, FP SRAM과 INT SRAM을 물리적으로 분리하고, HBM‑to‑Vector SRAM 스트리밍을 위한 Dequantizer와 Quantizer를 도입해 부동소수점·정수 데이터 흐름을 독립적으로 관리한다. 넷째, V_chunk 파라미터를 통해 vocab 를 청크 단위로 전처리·로드함으로써 온‑칩 SRAM이 제한된 엣지 디바이스에서도 확장성을 보장한다. 이러한 설계는 1 GHz 7 nm 공정에서 64 kB 이하 SRAM 사용 시에도 2배 이상 가속을 달성하고, 전체 로짓을 미리 로드한 경우 최대 2.53× RTX A6000 대비 성능 향상을 기록한다. 또한 사이클‑정확 시뮬레이터와 RTL 검증을 통해 수치 정확도와 기능 동등성을 입증하였다. 논문의 기여는 dLLM 샘플링을 위한 전용 하드웨어·ISA·메모리 계층을 체계적으로 정의하고, 기존 NPU 설계가 놓치고 있던 “비‑GEMM 중심” 워크로드를 효율적으로 처리할 수 있음을 실증한 점에 있다. 이는 차세대 AI 가속기가 AR‑LLM 뿐 아니라 diffusion‑LLM까지 포괄적으로 지원하도록 설계 패러다임을 전환하는 중요한 시사점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기