시각 파운데이션 모델을 제로샷 이상 탐지기로 전환하는 AnomalyVFM
초록
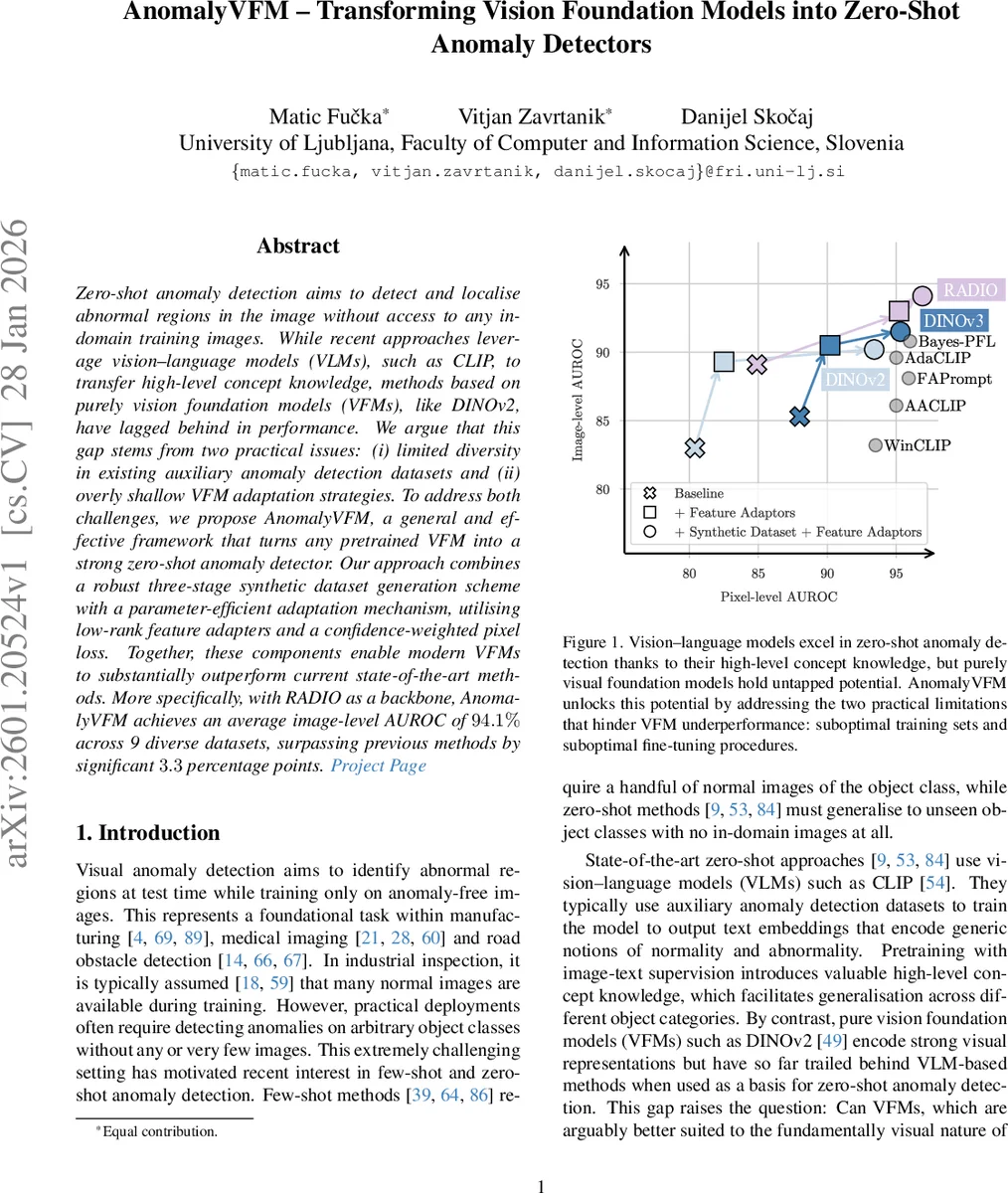
AnomalyVFM은 기존 비전 파운데이션 모델(VFM)을 활용해 제로샷 이미지 이상 탐지를 가능하게 하는 프레임워크이다. 세 단계의 합성 데이터 생성 파이프라인과 저차원 어댑터(LoRA)를 이용한 파라미터 효율적 미세조정, 그리고 신뢰도 가중 픽셀 손실을 결합해 VFM의 내부 표현을 효과적으로 변형한다. RADIO 백본을 사용했을 때 9개 산업 데이터셋에서 이미지‑레벨 AUROC 94.1%를 달성하며, 기존 최첨단 방법보다 평균 3.3%p 향상한다.
상세 분석
AnomalyVFM은 두 가지 근본적인 한계를 극복한다. 첫째, 기존 보조 이상 탐지 데이터셋은 객체 종류와 결함 형태가 제한적이어서 VFM이 일반화하기 어렵다. 이를 해결하기 위해 저자들은 최신 텍스트‑조건 이미지 생성 모델인 FLUX를 활용한 3단계 합성 파이프라인을 설계했다. ① 객체와 배경을 다양하게 조합해 정상 이미지(I)를 생성하고, ② 사전 학습된 Salient Object Segmentation 네트워크(IS‑Net)로 전경 마스크를 추출한 뒤, 무작위 위치와 크기로 결함 영역(R)을 샘플링한다. ③ “cracked”, “smudged” 등 객체에 맞는 결함 텍스트 프롬프트를 사용해 인페인팅을 수행하고, DINOv2 특징을 기반으로 코사인 거리 임계값을 적용해 결함이 제대로 삽입됐는지 자동 필터링한다. 이 과정은 인간 라벨링 없이도 수십만 장의 고품질 정상·비정상 이미지·마스크 삼중항을 생성한다는 점에서 데이터 다양성 확보에 큰 진전을 보인다.
두 번째 한계는 VFM을 얕게만 미세조정한다는 점이다. 기존 연구는 주로 최종 헤드에 작은 MLP를 붙이고 픽셀‑레벨 L1·Focal 손실만 적용했으며, 내부 트랜스포머 블록의 표현은 거의 변하지 않았다. AnomalyVFM은 LoRA(Low‑Rank Adaptation)를 각 트랜스포머 블록의 Query·Key·Value·Output projection에 삽입해 파라미터는 0.1% 수준으로 유지하면서도 내부 특징을 효율적으로 업데이트한다. LoRA의 랭크는 기본 64로 설정했으며, 이는 충분히 높은 표현력을 제공하면서도 과적합 위험을 낮춘다.
디코더는 적은 연산량의 2‑단계 업샘플링 컨볼루션 블록으로 구성돼, 적응된 특징을 픽셀‑레벨 이상 점수 맵(M_o)과 신뢰도 맵(c)으로 변환한다. 이미지‑레벨 이상 점수(A_o)는 CLS 토큰을 선형 레이어에 통과시켜 얻는다. 손실 함수는 두 부분으로 나뉜다. 이미지‑레벨은 Focal Loss를 사용해 클래스 불균형을 보정하고, 픽셀‑레벨은 L1 손실과 Focal 손실을 β=5 비율로 결합한다. 여기서 신뢰도 가중치 C=1+exp(c)를 도입해, 생성 과정에서 라벨이 불확실하거나 오류가 있는 경우 손실 기여도를 자동으로 감소시킨다. 이는 특히 합성 데이터의 노이즈에 강인한 학습을 가능하게 한다.
실험 결과는 설득력 있다. RADIO, DINOv2, DINOv3 등 세 가지 최신 VFM에 AnomalyVFM을 적용했을 때, 이미지‑레벨 AUROC가 각각 94.1%, 93.4%, 91.5%에 달했으며, 픽셀‑레벨 AUROC 역시 10~13%p 상승했다. 특히 9개의 산업용 MVTec‑AD, BTAD 등 벤치마크에서 기존 CLIP 기반 제로샷 방법을 3.3%p 앞선다. 의료 데이터셋에서도 전이 성능이 유지돼, 도메인 특화 라벨이 전혀 없는 상황에서도 활용 가능함을 보여준다. 또한, 몇 장의 정상 이미지만을 사용한 few‑shot 미세조정 실험에서도 최첨단 few‑shot 모델과 동등한 성능을 기록, 프레임워크의 범용성과 효율성을 입증한다.
요약하면, AnomalyVFM은 (1) 대규모·다양한 합성 데이터 생성, (2) 저차원 어댑터를 통한 내부 표현 업데이트, (3) 신뢰도 기반 손실 설계라는 세 축을 결합해 VFM을 제로샷 이상 탐지에 최적화한다. 파라미터 효율성, 데이터 독립성, 그리고 다양한 도메인에 대한 일반화 능력은 향후 산업·의료 현장에 바로 적용 가능한 실용적 솔루션으로 평가될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기