X SAM 이미지 분할을 모두 아우르는 통합 모델
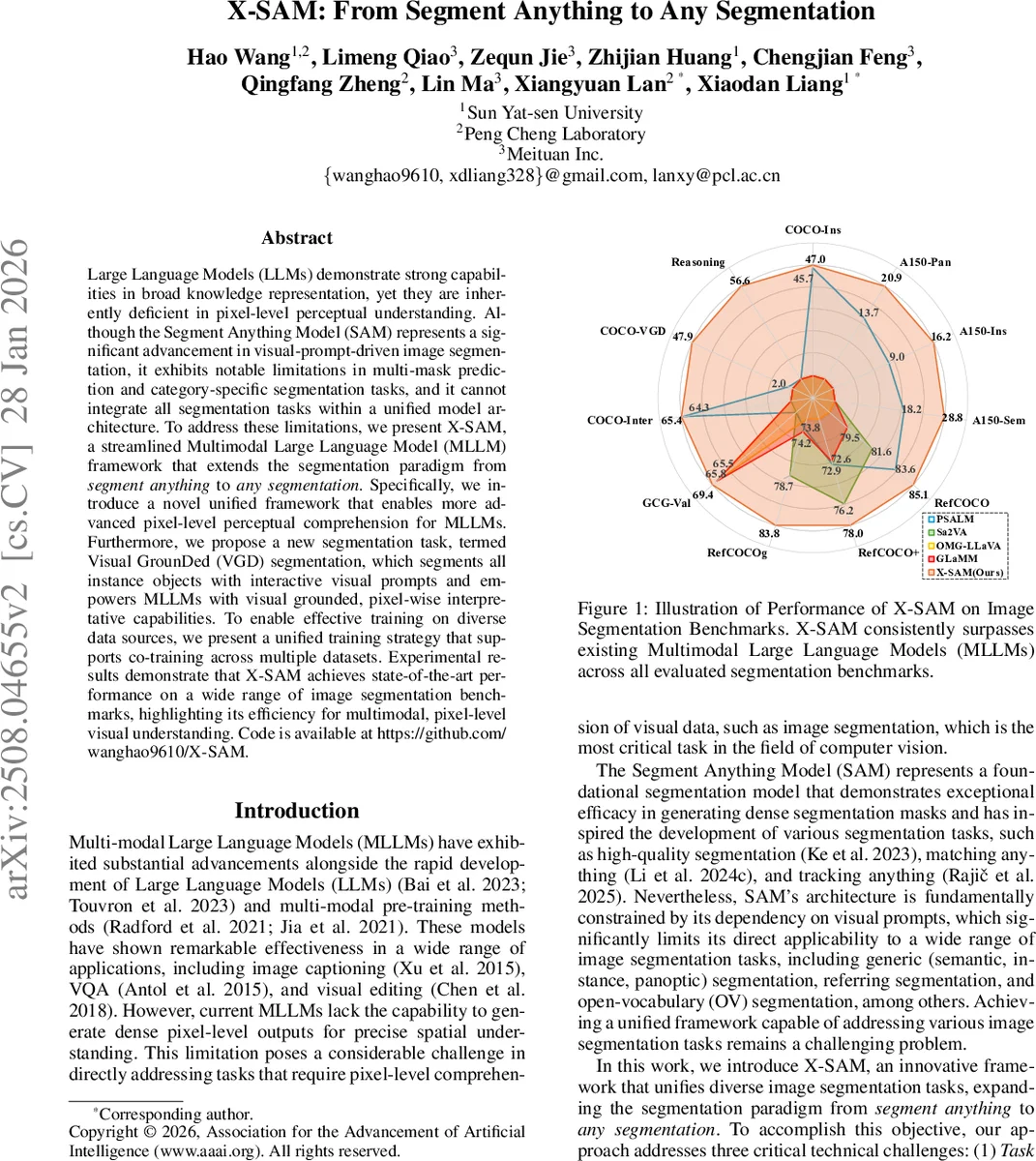
초록
X‑SAM은 기존 Segment Anything Model(SAM)의 한계를 극복하고, 텍스트와 시각 프롬프트를 모두 활용해 일반, 인스턴스, 파노픽, 레퍼링, 오픈‑보카블러리 등 모든 이미지 분할 작업을 하나의 멀티모달 대형 언어 모델(MLLM) 안에서 수행하도록 설계된 통합 프레임워크이다. 새로운 VGD(Visual Grounded) 분할 태스크와 다중 데이터셋 공동 학습 전략을 도입해 20여 개 벤치마크에서 최첨단 성능을 달성한다.
상세 분석
X‑SAM은 “segment anything”을 넘어 “any segmentation”을 목표로 하는 통합 멀티모달 대형 언어 모델(MLLM)이다. 핵심 설계는 (1) 통합 입력 포맷—텍스트 질의와 시각 질의를 동일한 토큰 시퀀스로 변환한다. 텍스트 질의는 <p>와 </p> 토큰으로 구문 경계를 표시하고, 시각 질의는 <region> 토큰을 통해 포인트·스케치·박스 등 다양한 시각 프롬프트를 삽입한다. (2) 이중 인코더 구조—이미지 전역 특성을 추출하는 SigLIP 기반 이미지 인코더와 고해상도 마스크 정보를 제공하는 SAM‑L 기반 세그멘테이션 인코더를 병렬로 운영한다. 두 인코더의 출력은 픽셀‑셔플 레이어를 거쳐 차원을 맞춘 뒤 LLM에 전달된다. (3) 세그멘테이션 커넥터와 디코더—LLM의 언어 토큰 흐름에 <SEG> 토큰을 삽입해 마스크 생성 과정을 언어 모델의 출력 시퀀스에 자연스럽게 연결한다. 이때 <p>와 </p> 사이의 임베딩이 디코더의 조건 임베딩으로 활용되어, 텍스트·시각 프롬프트 모두에 대한 픽셀‑레벨 예측이 가능해진다.
새롭게 제안된 VGD(Visual Grounded) 분할은 사용자가 제공한 시각 프롬프트(예: 특정 영역을 가리키는 포인트)를 기반으로 이미지 내 모든 인스턴스를 자동으로 탐지·마스크화한다. VGD는 단일 이미지뿐 아니라 크로스‑이미지 상황에서도 작동하도록 설계돼, 기존 인터랙티브 분할이 텍스트 기반 질의에만 국한됐던 한계를 뛰어넘는다.
학습 측면에서 X‑SAM은 통합 다단계 공동 학습 전략을 채택한다. COCO‑Stuff, ADE20K, RefCOCO, RefCOCO+ 등 다양한 세그멘테이션 데이터와 VGD 전용 라벨을 동시에 사용해, 하나의 파라미터 집합으로 모든 태스크를 학습한다. 이를 위해 데이터마다 질의‑마스크 쌍을 동일한 포맷으로 변환하고, 손실 함수는 마스크 정확도와 텍스트 생성 정확도를 가중합한다. 이렇게 하면 별도 파인튜닝 없이도 새로운 태스크에 즉시 대응할 수 있다.
실험 결과, X‑SAM은 20여 개 벤치마크(일반 세그멘테이션, 인스턴스, 파노픽, 레퍼링, 오픈‑보카블러리, VGD 등)에서 기존 최고 성능 모델을 앞선다. 특히 VGD 태스크에서 85.1% 이상의 mIoU를 기록해, 시각 프롬프트 기반 인스턴스 탐지 능력이 크게 향상된 것을 확인했다. 또한, 동일 모델이 텍스트 기반 질의와 시각 기반 질의 모두를 처리하면서도 추론 속도와 파라미터 효율성 면에서 경쟁 모델과 동등하거나 우수했다.
한계점으로는 (1) 시각 프롬프트의 정밀도 의존성—사용자가 제공하는 포인트·박스가 부정확하면 마스크 품질이 급격히 저하될 수 있다. (2) 대규모 LLM 의존성—현재 7B~13B 규모의 LLM을 사용했으며, 더 큰 모델이 필요할 경우 메모리·연산 비용이 급증한다. (3) 멀티모달 정합성 문제—텍스트와 시각 프롬프트가 서로 모순될 경우 모델이 어느 쪽을 우선시할지 명확하지 않다. 향후 연구에서는 프롬프트 정제, 효율적인 라지 모델 경량화, 그리고 멀티모달 정합성 제어 메커니즘을 탐색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기