AI 생성 이미지 출처 추적, 두 번 재구성으로 정확도 25% 상승
초록
AEDR은 훈련 없이도 생성 모델의 자동인코더를 두 차례 적용해 얻은 재구성 손실 비율을 이용해 이미지가 해당 모델에서 생성됐는지 판단한다. 이미지 복잡도 편향을 동질성 지표로 보정하고, 커널 밀도 추정으로 임계값을 자동 설정해 기존 단일 손실 기반 방법보다 평균 25.5% 높은 정확도와 1% 수준의 연산량을 달성한다.
상세 분석
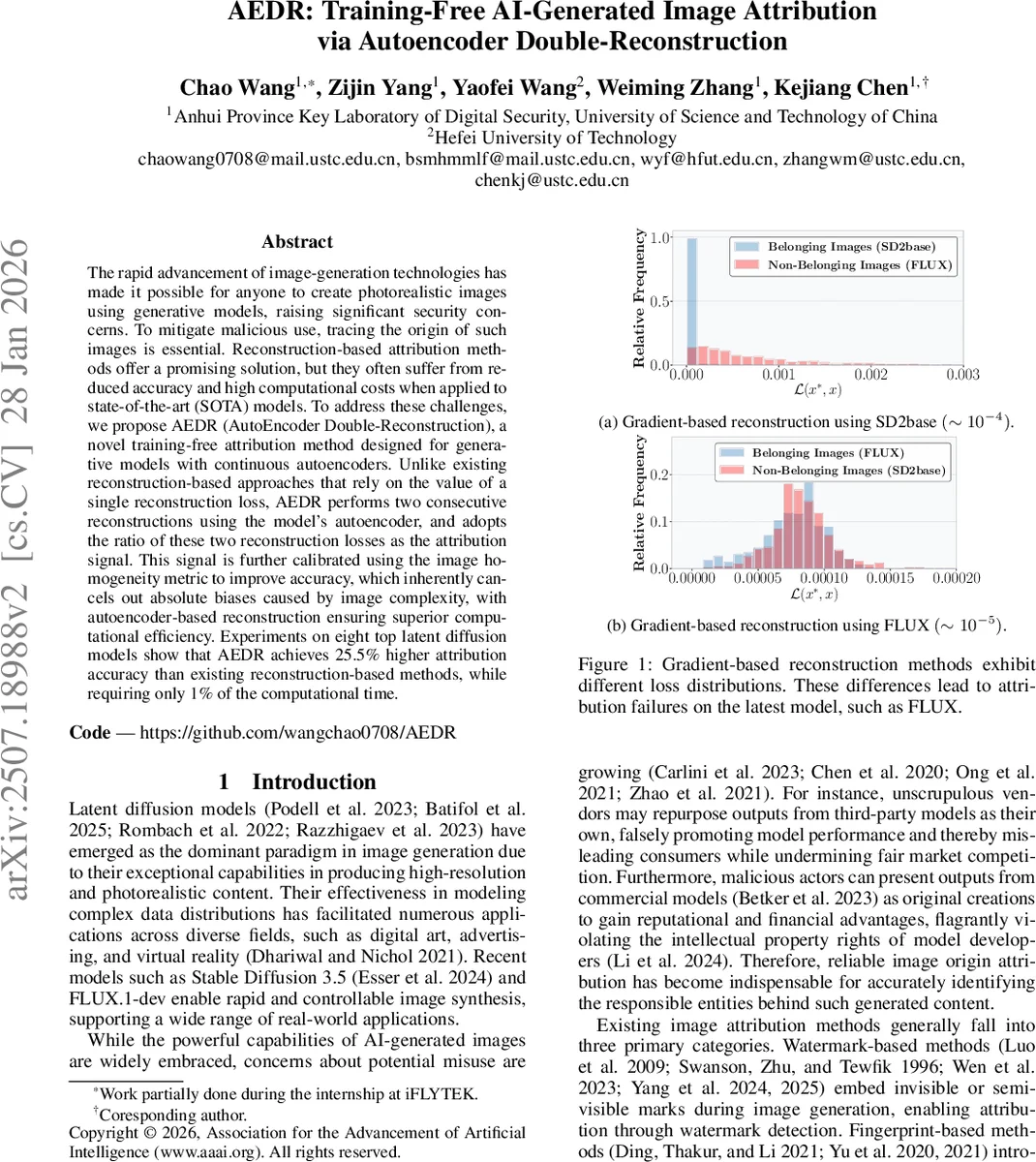
본 논문은 최신 확산 기반 이미지 생성 모델(LDM, Stable Diffusion 3.5, FLUX 등)의 급격한 성능 향상이 기존 재구성 기반 출처 추적 기법을 크게 약화시킨다는 점을 지적한다. 기존 방법은 모델의 그래디언트를 이용해 입력 이미지를 복원하고, 복원 손실이 낮을수록 해당 모델에 “속한다”는 가정을 한다. 그러나 최신 모델은 복원 손실 자체가 매우 낮아 belonging 이미지와 non‑belonging 이미지 사이의 손실 분포가 겹치게 되며, 이로 인해 정확도가 급격히 떨어진다. 또한 그래디언트 기반 복원은 수백 번의 최적화 반복을 필요로 하여 실시간 적용이 어렵다.
AEDR은 이러한 한계를 극복하기 위해 두 단계의 자동인코더 재구성을 도입한다. 첫 번째 재구성 L₁은 원본 이미지와 첫 번째 복원 이미지 사이의 MSE이며, 두 번째 재구성 L₂는 첫 번째 복원 이미지와 두 번째 복원 이미지 사이의 MSE이다. 핵심 아이디어는 “모델이 학습한 데이터 분포에 속하는 이미지”는 두 번 재구성해도 손실이 거의 변하지 않아 L₁/L₂≈1에 가깝지만, 분포 외 이미지(비속 이미지)는 첫 번째 재구성을 통해 어느 정도 분포 안으로 투영되므로 두 번째 손실이 현저히 감소하고 비율이 1보다 크게 된다.
하지만 이미지의 텍스처 복잡도는 절대 손실값에 큰 영향을 미친다. 저복잡도 이미지(단색 배경 등)는 손실이 작아 비율이 왜곡될 수 있다. 이를 보정하기 위해 논문은 동질성 지표 H를 도입한다. H는 회색조 공분포의 공기여빈도와 픽셀 간 강도 차이를 이용해 이미지가 얼마나 균일한지를 정량화한다. 최종 출처 판단 신호 t′= (L₁/L₂)·H는 복잡도 편향을 상쇄한다.
임계값 τ는 사전 정의된 비율이 아니라, belonging 이미지 500개에 대해 t′ 값을 커널 밀도 추정(KDE)으로 추정한 누적분포함수(CDF)에서 1−α(α=0.05) 지점으로 자동 결정한다. 이는 모델마다 손실 분포가 다를 때도 일관된 판단 기준을 제공한다.
실험에서는 8개의 최신 라티트 디퓨전 모델에 대해 AEDR을 평가했으며, 기존 Gradient‑based RONAN·LatentTracer 대비 평균 25.5% 높은 정확도와, 재구성에 소요되는 연산량이 기존 방법의 1% 수준에 불과함을 보고한다. 또한, 다양한 이미지 복잡도와 해상도에 대해 안정적인 성능을 유지한다는 추가 분석을 제공한다.
기술적 강점은 (1) 훈련·파라미터 접근이 필요 없는 완전 패시브 방식, (2) 자동인코더만 호출하면 되므로 GPU 메모리와 연산량이 크게 절감, (3) 손실 비율과 동질성 보정이라는 두 단계의 정규화가 복잡도 편향을 효과적으로 제거한다는 점이다. 한계로는 (가) 자동인코더가 모델에 내장돼 있지 않은 경우 적용이 어려우며, (나) MSE 손실에 의존함으로써 색상 변형이나 고주파 잡음에 민감할 수 있다. 향후 연구에서는 비선형 손실(예: LPIPS)이나 멀티‑스케일 인코더를 결합해 견고성을 높이는 방안을 모색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기