멀티모달 추론을 위한 최적화된 콜드 스타트와 단계적 강화학습
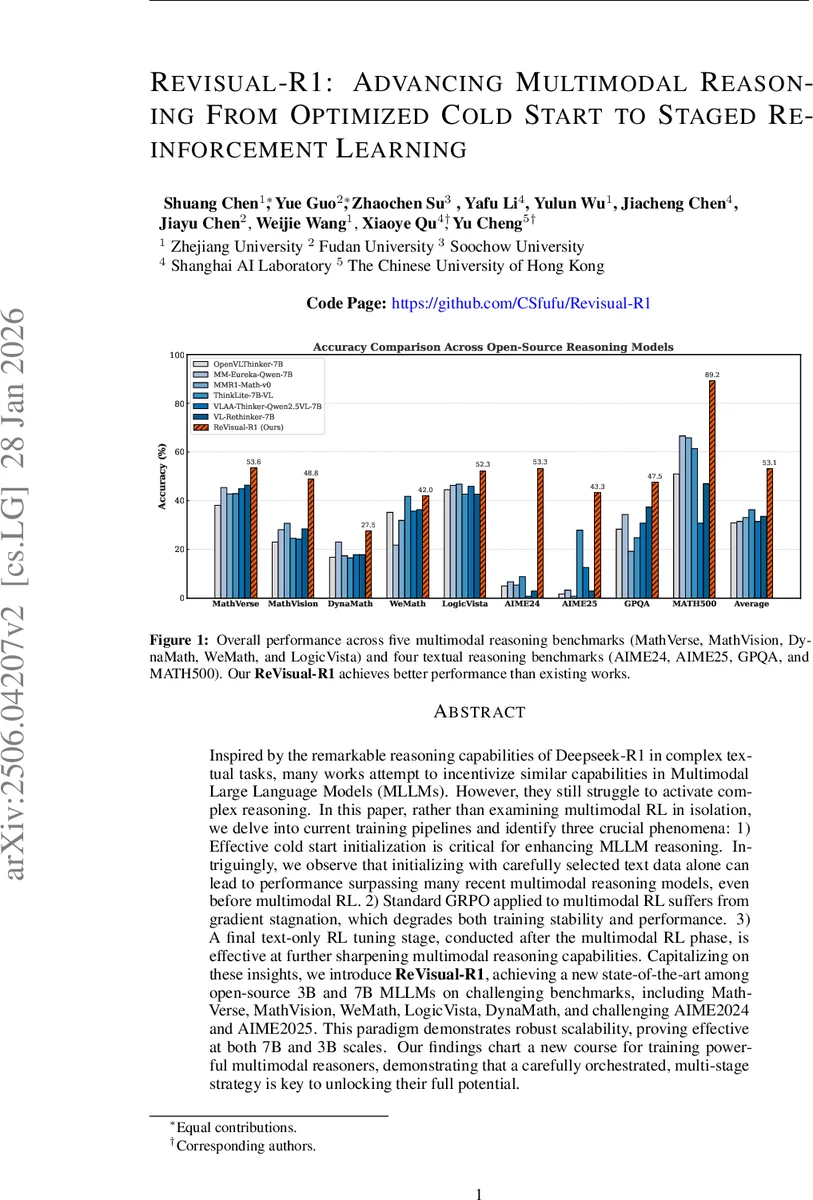
초록
본 논문은 멀티모달 대형 언어 모델(MLLM)의 복합 추론 능력을 끌어올리기 위해 세 가지 핵심 현상을 발견한다. 첫째, 텍스트 전용 고난이도 데이터로 이루어진 콜드 스타트가 모델의 사고 능력을 크게 향상시킨다. 둘째, 기존 GRPO 기반 멀티모달 강화학습에서 발생하는 ‘gradient stagnation’ 문제를 진단하고, 이를 완화하기 위한 Prioritized Advantage Distillation(PAD) 기법을 제안한다. 셋째, 멀티모달 RL 후 텍스트 전용 RL을 추가로 수행하면 시각적 정합성과 언어적 논리성이 동시에 강화된다. 이러한 3단계 학습 파이프라인을 적용한 ReVisual‑R1은 7B 파라미터 기준으로 MathVerse, MathVision, LogicVista 등 다섯 개 멀티모달 벤치마크와 AIME2024/25, GPQA 등 텍스트 추론 벤치마크에서 최첨단 성능을 달성한다.
상세 분석
본 연구는 멀티모달 추론 모델의 학습 흐름을 재조명하고, 기존 파이프라인이 놓치고 있던 세 가지 구조적 결함을 체계적으로 분석한다. 첫 번째 결함은 ‘콜드 스타트’ 단계에서 사용되는 데이터의 질이다. 기존 멀티모달 모델들은 시각‑언어 정합성을 위한 저난이도 이미지‑텍스트 쌍에 의존했지만, 이러한 데이터는 복잡한 논리 전개를 요구하지 않으므로 모델이 고차원 사고 체계를 습득하기 어렵다. 저자들은 텍스트 전용 고난이도 수학·논리 데이터(DeepMath, OpenR1‑Math 등)를 활용해 사전 학습을 진행함으로써, 모델 내부에 ‘Chain‑of‑Thought’와 자기‑반성 메커니즘을 미리 주입한다. 실험 결과, 이러한 텍스트‑중심 콜드 스타트만으로도 멀티모달 벤치마크에서 기존 멀티모달 콜드 스타트보다 평균 5~12%p의 절대적 향상을 보였다.
두 번째 결함은 멀티모달 강화학습에 적용되는 Group Relative Policy Optimization(GRPO)에서 발생하는 gradient stagnation이다. GRPO는 그룹별로 상대적 advantage를 계산해 정책을 업데이트하지만, 멀티모달 작업은 정답이 이진(0/1)으로 주어지는 경우가 많아 그룹 내 보상이 균일해지는 상황이 빈번하다. 이때 advantage가 거의 0에 수렴해 정책 그라디언트가 사라지고, 학습이 정체된다. 이를 해결하기 위해 제안된 Prioritized Advantage Distillation(PAD)은 (1) 각 시퀀스의 절대 advantage를 계산하고, (2) 일정 임계값 이하인 샘플을 필터링해 학습에 제외하며, (3) 남은 고신호 샘플에 가중치를 부여해 업데이트한다. 이렇게 하면 실제 학습에 기여하는 정보량이 집중돼, 훈련 안정성이 크게 개선되고 최종 성능이 3~7%p 상승한다.
세 번째 결함은 멀티모달 RL 이후 모델이 시각적 정합성을 강화하면서도 언어적 논리성을 유지하는 방법이 부족하다는 점이다. 저자들은 멀티모달 RL 단계가 끝난 뒤, 동일한 텍스트‑전용 RL을 추가 적용함으로써 ‘폴리싱’ 효과를 얻었다. 이 단계는 시각적 파라미터를 고정하거나 낮은 학습률로 미세 조정하면서, 텍스트 기반 추론 능력을 재강화한다. 결과적으로, 멀티모달 RL에서 얻은 시각적 grounding과 텍스트 RL에서 강화된 논리적 일관성이 시너지 효과를 내어, AIME와 같은 고난이도 수학 문제에서 인간 수준에 근접하는 정확도를 달성한다.
전체 파이프라인은 (1) 텍스트‑중심 고난이도 콜드 스타트, (2) PAD‑보강 GRPO 기반 멀티모달 RL, (3) 텍스트‑전용 RL 순으로 진행된다. 데이터 측면에서는 GRAMMAR라는 283K 텍스트와 21K 이미지‑텍스트 쌍으로 구성된 고품질 멀티모달 추론 데이터셋을 구축했으며, NV‑Embedding‑V2와 HDBSCAN을 활용해 다양성과 난이도를 균형 있게 샘플링했다. 실험에서는 7B 파라미터 ReVisual‑R1이 동일 규모의 공개 모델들을 크게 앞서며, 3B 모델에서도 유사한 스케일링 효과를 확인했다. 이러한 결과는 멀티모달 추론 모델 개발에 있어 ‘데이터의 질’, ‘알고리즘의 안정성’, ‘학습 단계의 순서’가 모두 중요함을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기