시계열 예측을 위한 모티프 기반 바이트 페어 인코딩
초록
본 논문은 시계열 데이터를 고정 길이 토큰이 아닌, 빈번히 등장하는 패턴(모티프)으로 압축하는 새로운 토크나이제이션 방식을 제안한다. 바이트 페어 인코딩을 확장해 연속적인 샘플을 가변 길이 토큰으로 합치고, 조건부 디코딩을 통해 양자화 오차를 보정한다. Chronos 기반의 대형 시계열 파운데이션 모델에 적용했을 때 예측 정확도는 평균 36 % 향상되고, 연산 효율은 1990 % 증가했으며, 조건부 디코딩으로 MSE가 최대 44 % 감소한다.
상세 분석
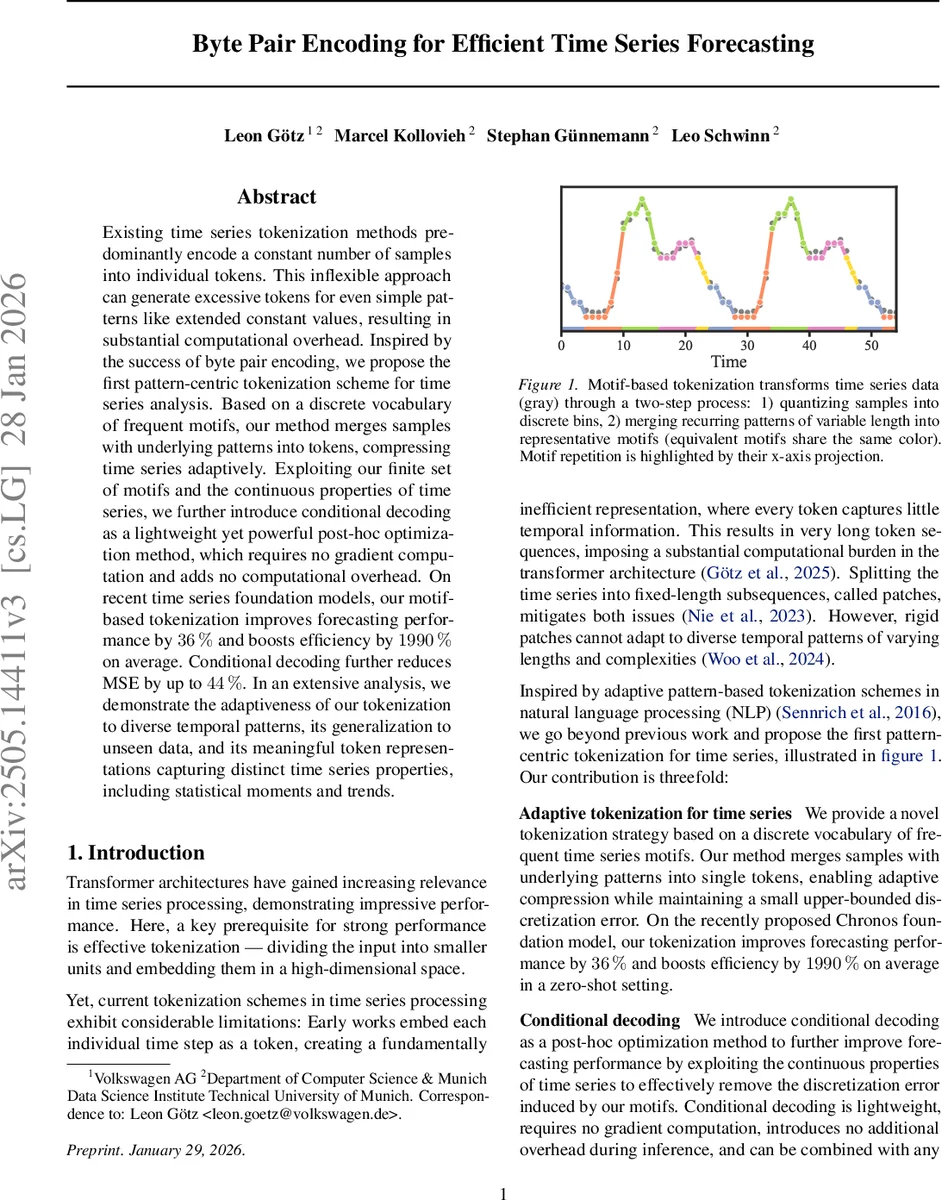
이 연구는 기존 시계열 토크나이제이션이 “샘플당 하나의 토큰” 혹은 “고정 길이 패치”라는 두 축에 머물러 있어, 장기 시계열에서 토큰 수가 급증하고 패턴 다양성을 포착하지 못한다는 근본적인 한계를 지적한다. 이를 해결하기 위해 저자들은 바이트 페어 인코딩(BPE)의 아이디어를 차용, 먼저 연속값을 일정 개수(M)의 구간으로 양자화하고, 양자화된 심볼 시퀀스에서 가장 빈번히 등장하는 인접 심볼 쌍을 반복적으로 병합해 “모티프”라는 가변 길이 토큰 사전을 구축한다. 이 과정은 데이터에 기반한 빈도 분석이므로, 실제 시계열에서 자주 나타나는 트렌드, 계절성, 급격한 변동 등을 자연스럽게 토큰화한다.
양자화 단계에서 저자들은 균등, 가우시안, 데이터 분포 기반 등 다양한 구간 설정을 실험했으며, 최대 양자화 오차 δ_max를 명시적으로 제어한다. 모티프 사전 구축은 최소 발생 빈도 p_min을 기준으로 진행돼, 학습에 충분한 샘플을 보장한다. 결과적으로 토큰 수 t는 원본 길이 n에 비해 크게 감소(압축 비율 2.084.06)하고, 사전 크기 V는 1 3002 400 수준으로 제한된다.
조건부 디코딩은 양자화 후 발생하는 오차를 일차 마코프 가정 하에, 이전 토큰을 조건으로 각 심볼에 최적의 실수값(평균) ω̂_{j,k}를 할당함으로써 보정한다. 이 과정은 폐쇄형 해를 갖는 최소제곱 문제이며, 추가 연산 비용이 거의 없고 파라미터 수도 M²에 불과해 경량화된 사후 최적화 기법으로 평가된다.
실험에서는 Chronos 파운데이션 모델을 기반으로, 제안된 모티프 토크나이저와 기존 샘플‑기반, 패치‑기반 토크나이저를 동일 조건에서 비교했다. 5개의 벤치마크(ETTh1, ETTm1, Weather, Electricity, Traffic)에서 제로샷 설정으로 평가했으며, 평균 MSE 개선율이 36 %에 달하고, 연산량(플롭스) 기준 효율은 1990 % 향상되었다. 특히 고압축(Compression 4.06) 설정에서 조건부 디코딩을 적용했을 때 MSE가 추가로 44 % 감소하는 효과를 보였다.
기술적 강점은 (1) 데이터‑주도적 패턴 추출로 다양한 시계열 특성을 자연스럽게 반영, (2) 토큰 수 감소에 따른 메모리·시간 효율성, (3) 조건부 디코딩을 통한 양자화 오차 최소화이며, 이는 기존 고정‑패치 방식이 놓치던 장기 의존성 및 비선형 변동을 보존한다. 한편 제한점으로는 (①) 사전 구축 단계가 전체 데이터에 대한 빈도 분석을 필요로 하여 사전 학습 비용이 존재, (②) 매우 드문 패턴은 토큰화되지 않을 위험, (③) 현재는 1차 마코프 가정에 의존하므로 복잡한 상관관계가 있는 다변량 시계열에는 확장성이 제한될 수 있다. 향후 연구에서는 다변량 모티프 사전, 동적 p_min 조정, 그리고 조건부 디코딩을 고차 마코프 혹은 신경망 기반 보정기로 확장하는 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기