LLM 전용 파인튜닝으로 AI 생성 텍스트 탐지 효율 극대화
초록
본 논문은 1 조 토큰 규모의 인간 텍스트와 1.9 조 토큰 규모의 AI 생성 텍스트를 구축하고, LLM별·LLM군별 파인튜닝 전략을 적용한 탐지 모델을 제안한다. 21개 대형 모델을 포함한 100 백만 토큰 벤치마크에서 최고 99.6 % 토큰‑레벨 정확도를 달성하며, 기존 오픈소스 탐지기 대비 큰 성능 향상을 보였다.
상세 분석
이 연구는 AI 생성 텍스트 탐지 분야에서 데이터 규모와 모델 특화 파인튜닝이라는 두 축을 동시에 확장한 점이 가장 큰 강점이다. 먼저, 저자들은 10개의 인간 텍스트 데이터셋(블로그, 에세이, 뉴스, 토론, 창작 등)을 통합해 1 조 토큰 규모의 인간 코퍼스를 구축하였다. 이어서 21개의 최신 LLM(오픈AI GPT‑4, Meta Llama‑3, Microsoft Phi‑4, Mistral, Alibaba Qwen 등)을 활용해 동일한 프롬프트 템플릿을 적용, 네 가지 샘플링 파라미터(Deterministic, Balanced, Creative, Highly Creative)를 무작위로 배정해 1.9 조 토큰 규모의 AI 생성 코퍼스를 만든다. 이 과정에서 프롬프트 설계, 토큰 길이 제한(≤ 8192), 사후 정제(공백·중복 제거) 등 품질 관리 절차를 상세히 기술했으며, 데이터 균형을 위해 토큰 수 기반 샘플링 알고리즘을 도입했다.
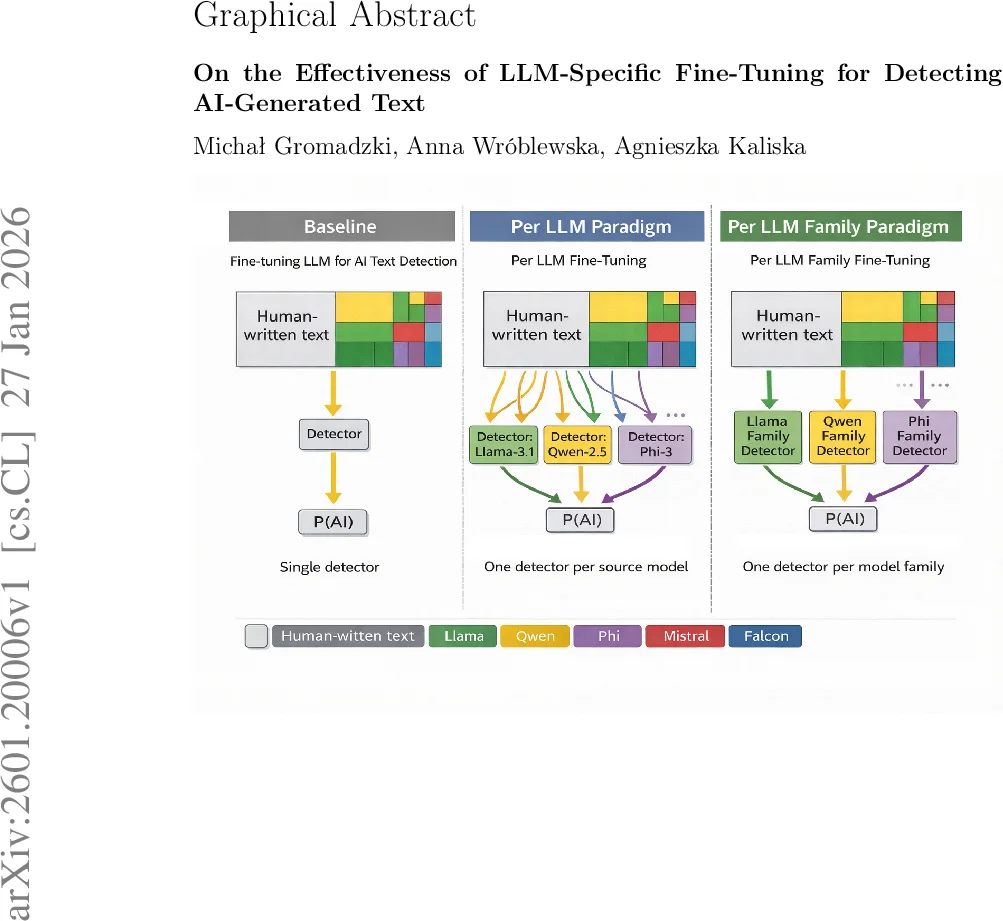
탐지 모델은 RoBERTa‑large 기반의 이진 분류기로, 두 가지 파인튜닝 전략을 실험했다. ‘Per LLM’ 파인튜닝은 각 LLM별로 별도 모델을 학습해 해당 모델이 생성한 텍스트에 최적화된 탐지기를 만든다. 반면 ‘Per LLM Family’ 파인튜닝은 동일한 아키텍처·하이퍼파라미터를 유지하면서 LLM군(예: Meta, Microsoft, Alibaba) 단위로 데이터를 통합해 하나의 모델을 학습한다. 이렇게 하면 모델 수를 크게 줄이면서도 군내 일반화 성능을 확보할 수 있다.
실험 결과, Per LLM 파인튜닝은 특정 모델에 대해 99.2 %99.6 %의 토큰‑레벨 정확도를 기록했으며, Per LLM Family 파인튜닝도 98.7 % 수준으로 높은 성능을 유지했다. 특히, 기존 오픈소스 탐지기(DetectGPT, Fast‑DetectGPT 등)와 비교했을 때 평균 712 % 포인트 이상의 정확도 향상이 관찰되었다. 또한, 다양한 도메인(블로그, 뉴스, 소셜 미디어 등)과 길이(짧은 트윗부터 긴 기사까지)에서 일관된 성능을 보였으며, 샘플링 파라미터 변동에 대한 강인성도 검증했다.
한계점으로는 (1) 프롬프트 템플릿이 인간 텍스트와 1:1 매핑되는 구조에 의존해 실제 자유형 입력에 대한 일반화가 제한될 수 있다. (2) 파인튜닝에 사용된 LLM이 제한된 21개에 머물러 있어, 향후 새로운 모델이 등장하면 재학습이 필요하다. (3) 토큰‑레벨 정확도는 높지만, 문서‑레벨(예: 전체 논문, 보고서)에서의 실용적 판단 기준은 별도 평가가 필요하다.
전반적으로, 대규모 균형 코퍼스와 모델‑특화 파인튜닝이 AI 생성 텍스트 탐지 성능을 비약적으로 끌어올릴 수 있음을 실증했으며, 향후 실무 적용을 위한 데이터·모델 관리 프레임워크를 제시한다는 점에서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기