길이 적응 관심 네트워크로 CTR 예측의 장단기 시퀀스 균형 맞추기
초록
사용자 행동 시퀀스 길이의 이질성을 고려하지 않으면 짧은 이력 사용자의 클릭‑예측 성능이 떨어진다. 논문은 시퀀스 길이를 명시적 조건으로 활용하는 LAIN 프레임워크를 제안한다. 스펙트럼 길이 인코더로 길이를 연속 임베딩으로 변환하고, 길이‑조건 프롬프트와 길이‑조절 어텐션을 통해 짧은 시퀀스와 긴 시퀀스를 동시에 최적화한다. 주요 CTR 모델에 플러그인 방식으로 적용했을 때 AUC가 최대 1.15 %p, 로그손실이 2.25 %p 개선되는 효과를 보였다.
상세 분석
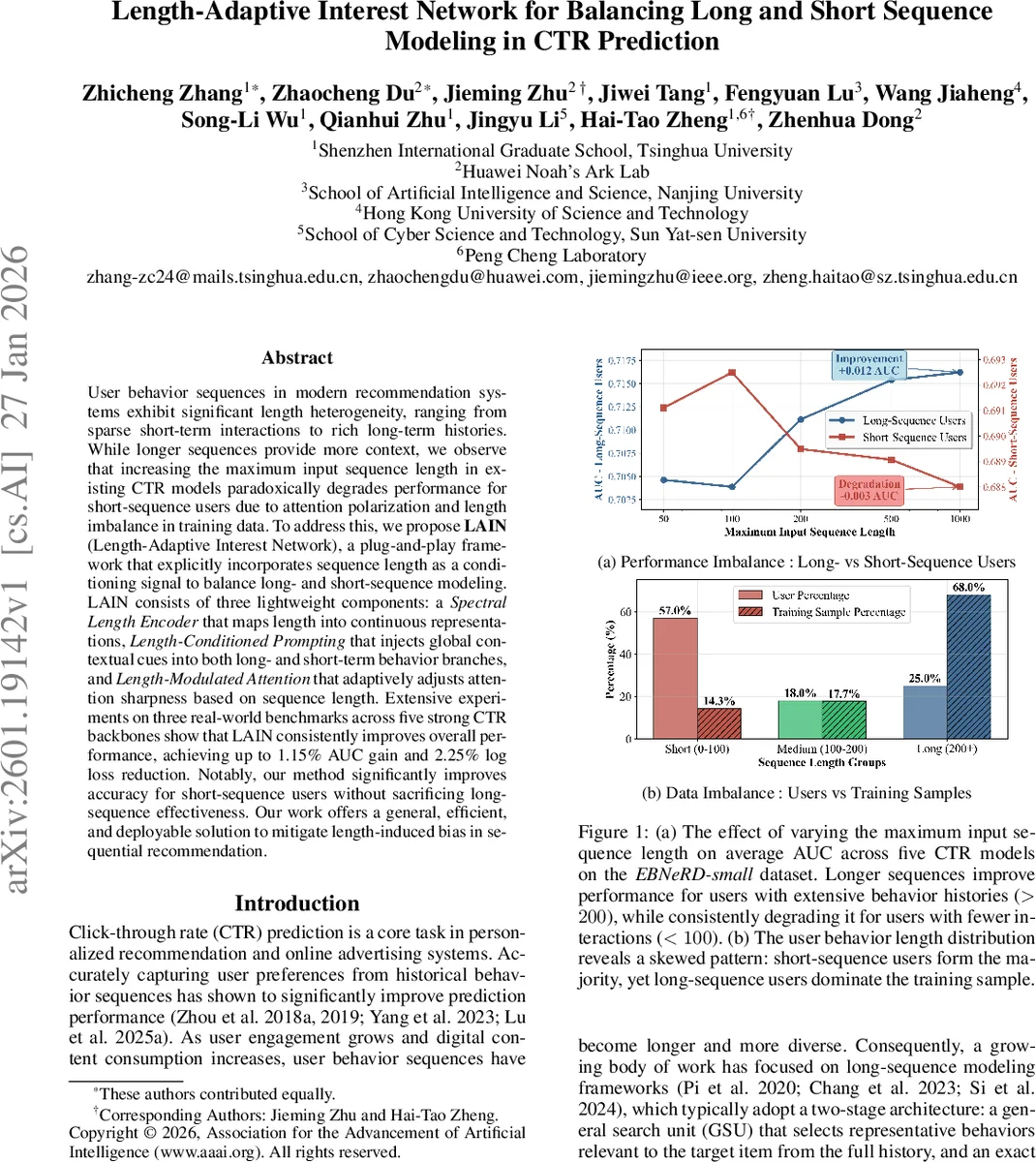
본 논문은 현재 상용 CTR 모델이 “하나의 아키텍처로 모든 길이의 시퀀스를 처리한다”는 전제 하에, 시퀀스 길이가 짧은 사용자(대다수)와 긴 사용자(소수) 사이에 성능 격차가 발생한다는 문제를 정량적으로 진단한다. 저자들은 두 가지 핵심 원인을 제시한다. 첫째, 소프트맥스 기반 어텐션은 입력 길이가 늘어날수록 가중치가 소수의 토큰에 집중되는 ‘어텐션 편극(attention polarization)’ 현상이 심화된다. 짧은 시퀀스에서는 제한된 토큰 수 때문에 몇몇 토큰에 과도하게 집중되어 남은 신호를 활용하지 못한다. 둘째, 기존 모델은 시퀀스 길이를 전혀 활용하지 않는 ‘길이 신호 결핍(length signal deficiency)’ 문제를 가지고 있다. 길이는 사용자의 활성도, 관심 다양성, 행동 안정성 등을 반영하는 강력한 메타 정보임에도 불구하고 모델 입력에 포함되지 않는다. 이러한 두 요인은 서로 상쇄되는 그래디언트 신호를 만들어, 긴 시퀀스에 최적화된 파라미터와 짧은 시퀀스에 최적화된 파라미터가 충돌하게 만든다.
이를 해결하기 위해 제안된 LAIN은 세 가지 경량 모듈로 구성된다. ① **Spectral Length Encoder (SLE)**는 원시 길이 L을 푸리에 기반의 연속 함수를 통해 고차원 임베딩 h_len으로 변환한다. 이 임베딩은 주기적 특성을 갖추어 길이 차이를 부드럽게 구분한다. ② **Length‑Conditioned Prompting (LCP)**는 h_len을 이용해 길이‑특정 프롬프트 토큰을 생성하고, 이를 행동 시퀀스 앞에 삽입한다. 프롬프트는 전역 컨텍스트를 제공함으로써 짧은 시퀀스에도 충분한 정보가 전달되도록 한다. ③ **Length‑Modulated Attention (LMA)**는 어텐션 스코어에 동적 온도 τ(L)를 적용해 부드러운 어텐션(짧은 시퀀스)과 날카로운 어텐션(긴 시퀀스)을 자동 전환한다. 또한 키·쿼리 벡터에 h_len을 직접 더해 길이 의존성을 강화한다.
모듈들은 기존 CTR 파이프라인에 플러그인 형태로 삽입될 수 있어 파라미터 증가가 미미하고, 추론 지연도 거의 없으며, 다양한 백본(예: DIN, DIEN, SIM, ET‑A, TWIN)에서 일관된 성능 향상을 보였다. 실험 결과, 전체 AUC가 평균 0.8 %p 상승하고, 특히 짧은 시퀀스(≤100) 사용자군에서 AUC가 2 %p 이상 개선되었다. 로그 손실 역시 전체 1.5 %p, 짧은 군에서 2.25 %p 감소하였다.
이러한 설계는 ‘길이‑조건화’라는 새로운 inductive bias를 모델에 주입함으로써, 데이터 불균형에 의한 편향을 완화하고, 짧은 이력 사용자의 콜드‑스타트 문제를 완화한다는 점에서 실무적·학술적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기