계층적 인터프레임 상관관계를 활용한 원샷 포인트 클라우드 시퀀스 압축
초록
**
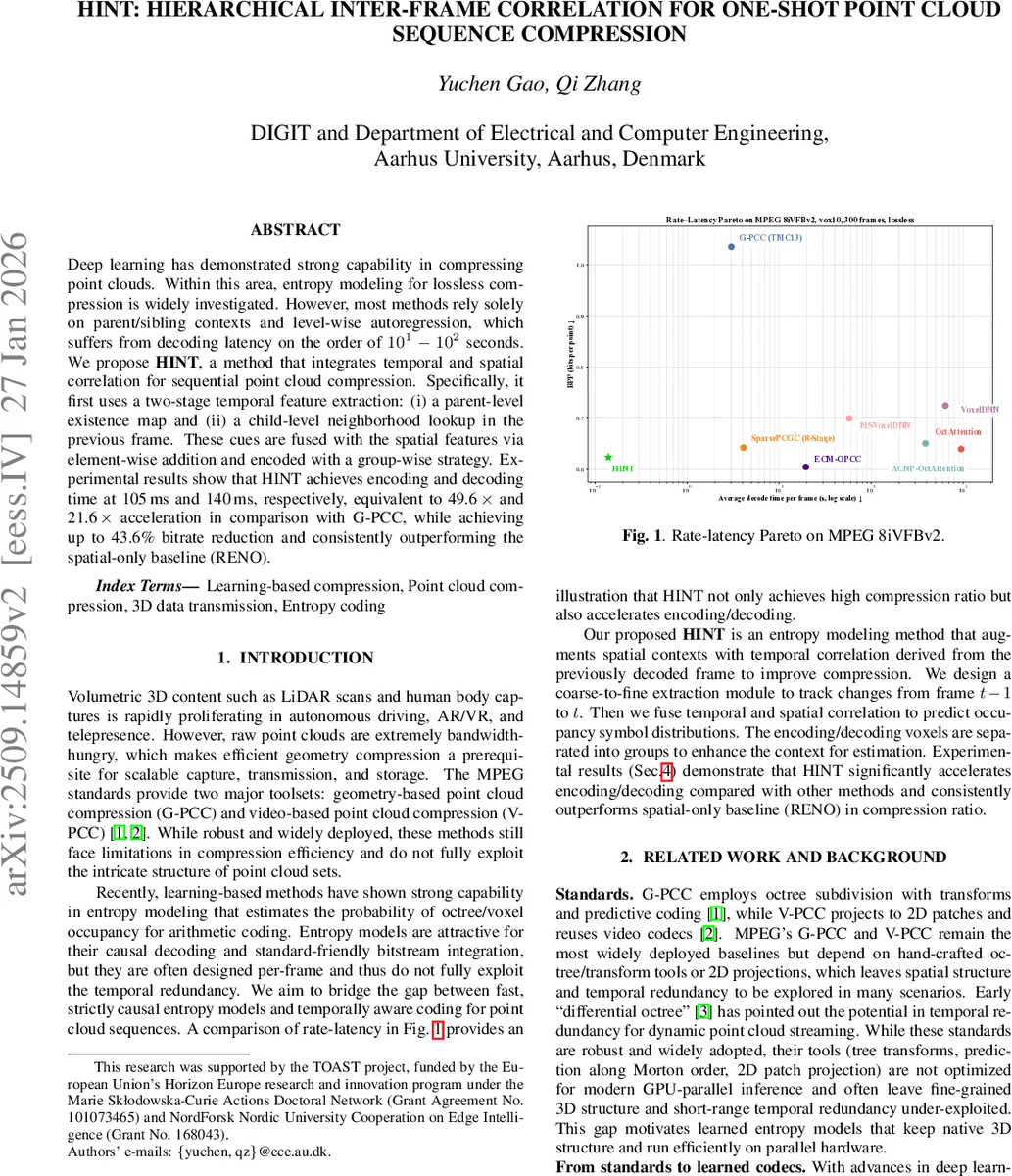
HINT는 이전 프레임의 존재 맵과 이웃 검색을 이용해 시간적 특징을 추출하고, 이를 공간적 특징과 결합해 그룹 단위로 엔트로피를 모델링한다. 결과적으로 G‑PCC 대비 49.6배 빠른 인코딩·140 ms 디코딩을 달성하면서 비트당 포인트(BPP)를 최대 43.6 % 절감한다.
**
상세 분석
**
본 논문은 포인트 클라우드 시퀀스 압축에서 기존 학습 기반 엔트로피 모델이 부모·형제 컨텍스트와 레벨‑와이즈 자동회귀에만 의존해 디코딩 지연이 수초에 달한다는 문제점을 지적한다. 이를 해결하기 위해 제안된 HINT는 두 단계의 시간적 특징 추출 모듈을 도입한다. 첫 번째 단계인 ‘부모‑레벨 존재 맵’은 현재 프레임 t와 이전 프레임 t‑1의 동일 레벨 부모 voxel에 대해 3×3×3(또는 5×5×5) 이웃 존재 여부를 0/1 벡터로 수집하고, 이를 MLP에 통과시켜 32차원 시간적 특징 T_d를 만든다. 두 번째 단계인 ‘자식‑레벨 세밀한 검색’은 현재 프레임의 자식 voxel에 대해 t‑1 프레임의 동일 위치와 주변(5×5×5) voxel의 8비트 점유 코드를 임베딩 테이블을 통해 32차원 벡터 e_δ 로 변환한 뒤 평균화하고 선형 변환 W_t 로 T_{d+1} 를 얻는다. 이 두 특징은 각각 공간적 특징 F_s (RENO의 Prior ResNet에서 추출)와 요소‑별 덧셈으로 결합되어 최종 자식‑레벨 특징 F_{d+1}=F_d+T_{d+1} 를 만든다.
특징 결합 이후 HINT는 ‘짝수·홀수 그룹’ 전략으로 자식 voxel을 두 그룹(G_e, G_o)으로 나눈다. G_e에 대해 기존 RENO와 동일하게 4비트 하위(s0)와 상위(s1) 확률을 순차적으로 예측하고, 예측된 s0를 임베딩해 F_{d+1}에 추가해 s1를 예측한다. G_o는 이미 디코딩된 G_e의 8비트 점유 코드를 256‑entry 임베딩으로 변환하고, 각 voxel의 3차원 상대 위치와 결합해 선형 변환 W_s 로 ‘형제 컨텍스트’ F(G_e)를 만든다. 이 형제 컨텍스트를 F_{d+1}에 더해 ˜F_{d+1}=F_{d+1}+F(G_e) 로 풍부한 조건을 제공하고, 동일한 두 단계 예측 파이프라인을 적용한다. 이 설계는 ‘짝수·홀수’ 패리티가 서로 교차하므로, 홀수 voxel은 이미 디코딩된 짝수 형제만을 참조하게 되어 엄격한 인과성을 유지한다.
실험에서는 MPEG 8iVFBv2 시퀀스(Loot, Longdress, Redandblack, Soldier)를 10‑bit 양자화 후 300 프레임 전체에 대해 평균 BPP와 인코딩·디코딩 시간을 측정했다. HINT는 G‑PCC 대비 인코딩 49.6배, 디코딩 21.6배 가속을 보였으며, 비트당 포인트는 최대 43.6 % 감소했다. 특히 정적인 구간에서는 4‑5 %(최대 6.7 %)의 추가 절감 효과가 관찰되었다. 모델 크기는 3.4 MB로 SparsePCGC(4.9 MB)보다 작으며, 연산 복잡도 역시 크게 낮아 실시간 혹은 근실시간 응용에 적합하다.
핵심 기여는 (1) 기존의 공간‑전용 엔트로피 모델에 가벼운 시간적 신호(존재 맵·이웃 점유)와 이를 효율적으로 결합한 점, (2) 패리티 기반 그룹화로 형제 간 상호작용을 강화하면서도 자동회귀를 최소화해 지연을 크게 줄인 점, (3) 고밀도 LiDAR뿐 아니라 MPEG 표준 시퀀스까지 일반화 가능함을 실증한 점이다. 이러한 설계는 GPU 병렬 처리에 최적화된 sparse tensor 연산(TorchSparse)과 경량 MLP/MLP‑like 모듈만을 사용해 구현되었으며, 향후 비디오 기반 포인트 클라우드 압축(V‑PCC)과의 하이브리드에도 확장 가능성을 시사한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기