온정책 데이터가 항상 최선인가? 직접 선호 최적화 기반 LM 정렬의 단계적 분석
초록
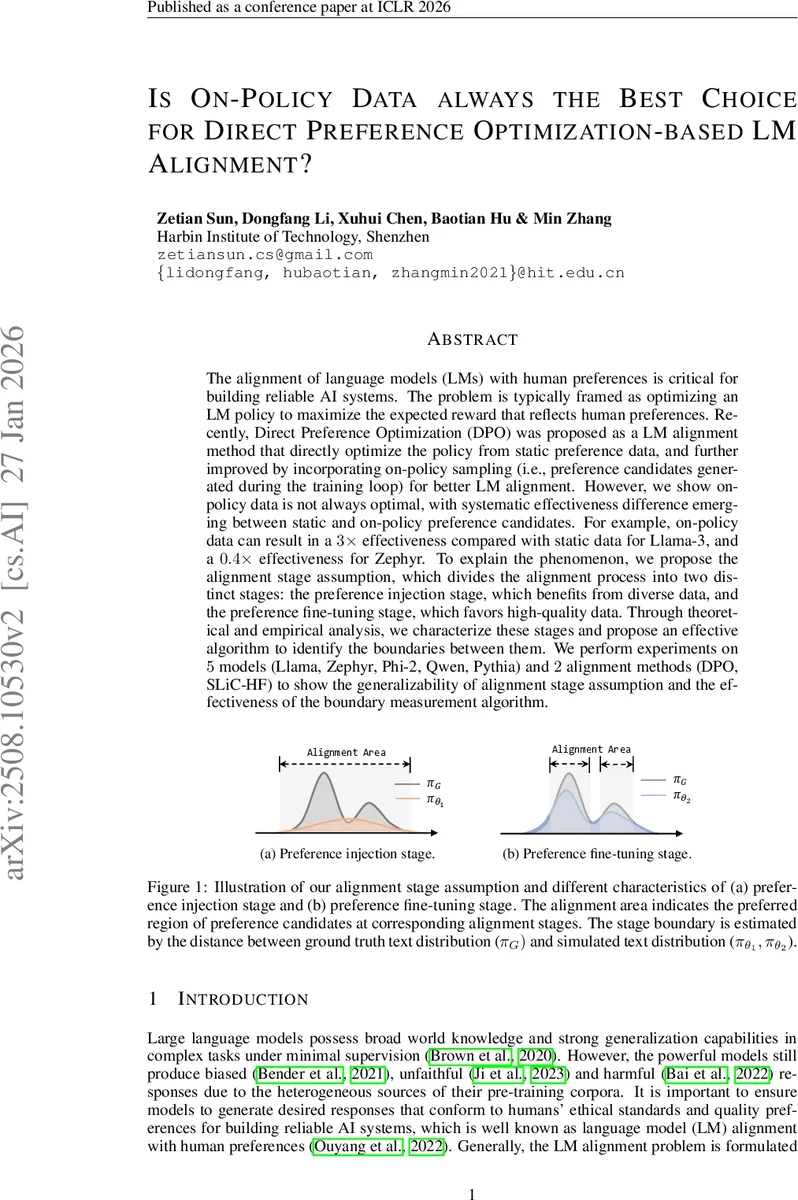
본 논문은 Direct Preference Optimization(DPO)과 같은 오프‑정책 정렬 방법에 온‑정책 샘플을 혼합했을 때, 모델마다 효과가 크게 달라진다는 사실을 발견한다. 이를 설명하기 위해 정렬 과정을 ‘선호 주입 단계’와 ‘선호 미세조정 단계’로 구분하는 “정렬 단계 가정”을 제시하고, 현재 정책이 어느 단계에 있는지를 판단하는 경계 측정 알고리즘을 개발한다. 5개 모델(Llama‑3, Zephyr, Phi‑2, Qwen, Pythia)과 2가지 정렬 기법(DPO, SLiC‑HF)에 대한 실험을 통해 가정의 일반성과 알고리즘의 실효성을 검증한다.
상세 분석
이 논문은 최근 주목받는 직접 선호 최적화(DPO) 방식에 온‑정책 데이터를 추가하는 것이 항상 이득이 되는 것이 아님을 실험적으로 입증한다. Llama‑3에서는 온‑정책 데이터가 정렬 효율을 3배까지 끌어올리는 반면, Zephyr에서는 오히려 0.4배로 감소한다는 극단적인 차이를 보고한다. 이러한 현상은 모델의 규모·학습 단계·초기 파라미터 상태에 따라 선호 데이터의 ‘다양성’과 ‘품질’이 요구되는 시점이 다르기 때문이라고 저자는 주장한다.
‘정렬 단계 가정’은 정렬 과정을 두 단계로 나눈다. 첫 번째인 선호 주입 단계에서는 정책이 아직 인간 선호를 충분히 반영하지 못한 상태이므로, 다양한 후보(다양한 토큰 분포와 다양한 선호 라벨)를 제공해 일반적인 보상 분포를 빠르게 추정하는 것이 핵심이다. 이때 온‑정책 샘플이 새로운 텍스트 공간을 탐색하므로, 데이터 다양성이 크게 기여한다. 두 번째인 선호 미세조정 단계에서는 정책이 이미 기본적인 보상 구조를 학습했으므로, 고품질(높은 승률을 가진) 후보에 집중해 미세한 성능 향상을 도모한다. 여기서는 온‑정책 데이터가 기존 오프‑정책 데이터보다 품질이 낮을 경우 오히려 성능 저하를 초래한다.
이를 정량화하기 위해 저자는 경계 측정 알고리즘을 제안한다. 정책 πθ와 오프‑정책 데이터 기반 시뮬레이션 분포 π_off, 그리고 현재 모델이 생성한 온‑정책 분포 π_on 사이의 KL·JS 거리 혹은 브래들리-터리 일관성 점수를 계산한다. 두 거리 중 어느 쪽이 실제 인간 선호(또는 PairRM으로 대체한 ‘ground‑truth’ 보상)와 더 가깝게 매핑되는지를 판단함으로써, 현재 정책이 주입 단계에 있는지 미세조정 단계에 있는지를 자동으로 식별한다.
이론적 분석에서는 브래들리-터리 모델 하에서 선호 데이터의 다양성이 전체 텍스트 분포를 더 정확히 근사하는 데 기여한다는 점을 증명한다. 즉, 다양성이 높을수록 보상 함수 rϕ가 실제 인간 선호를 잘 반영하는 확률분포 π_G에 가까워진다. 반면, 품질이 높은 데이터는 KL 정규화 항을 최소화하면서 정책을 π_G에 수렴시키는 데 유리하다.
실험 설계는 두 번의 반복 학습(두 단계)으로 구성되며, 각 단계마다 오프‑정책(PC_off)과 온‑정책(PC_on) 데이터를 교차 적용한다. 네 가지 조합(PC_off→off, PC_off→on, PC_on→off, PC_on→on)을 모든 모델에 적용해 AlpacaEval 2.0 기준 승률을 측정한다. 결과는 Llama‑3이 전반적으로 PC_on을 선호하는 반면, Zephyr와 Phi‑2는 초기 단계에서는 PC_off이 유리하고, 후반 단계에서는 PC_on이 도움이 되는 복합적인 패턴을 보여준다. 또한 SLiC‑HF에도 동일한 경향이 나타나, 제안된 단계 가정이 DPO에 국한되지 않음을 입증한다.
전체적으로 이 논문은 “데이터 다양성 vs. 품질”이라는 두 축을 정렬 과정에 명시적으로 연결하고, 모델·단계에 따라 최적의 데이터 선택 전략을 자동화할 수 있는 실용적인 도구를 제공한다는 점에서 의미가 크다. 향후 연구에서는 경계 측정 기준을 더 정교화하거나, 인간 피드백을 직접 활용한 실시간 단계 전이 제어 메커니즘을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기