시각 중심 질문응답을 위한 R3G: 추론‑검색‑재정렬 통합 프레임워크
초록
R3G는 질문과 이미지에서 필요한 시각적 단서를 먼저 추론하고, 거친 이미지 검색과 의미‑정밀 재정렬을 결합해 최적의 증거 이미지를 선택한다. 두 단계 검색과 재정렬 점수(시맨틱 연관성, 목표 일치성, 답변 가능성)를 활용해 기존 MRAG 대비 전반적인 정확도를 크게 향상시킨다.
상세 분석
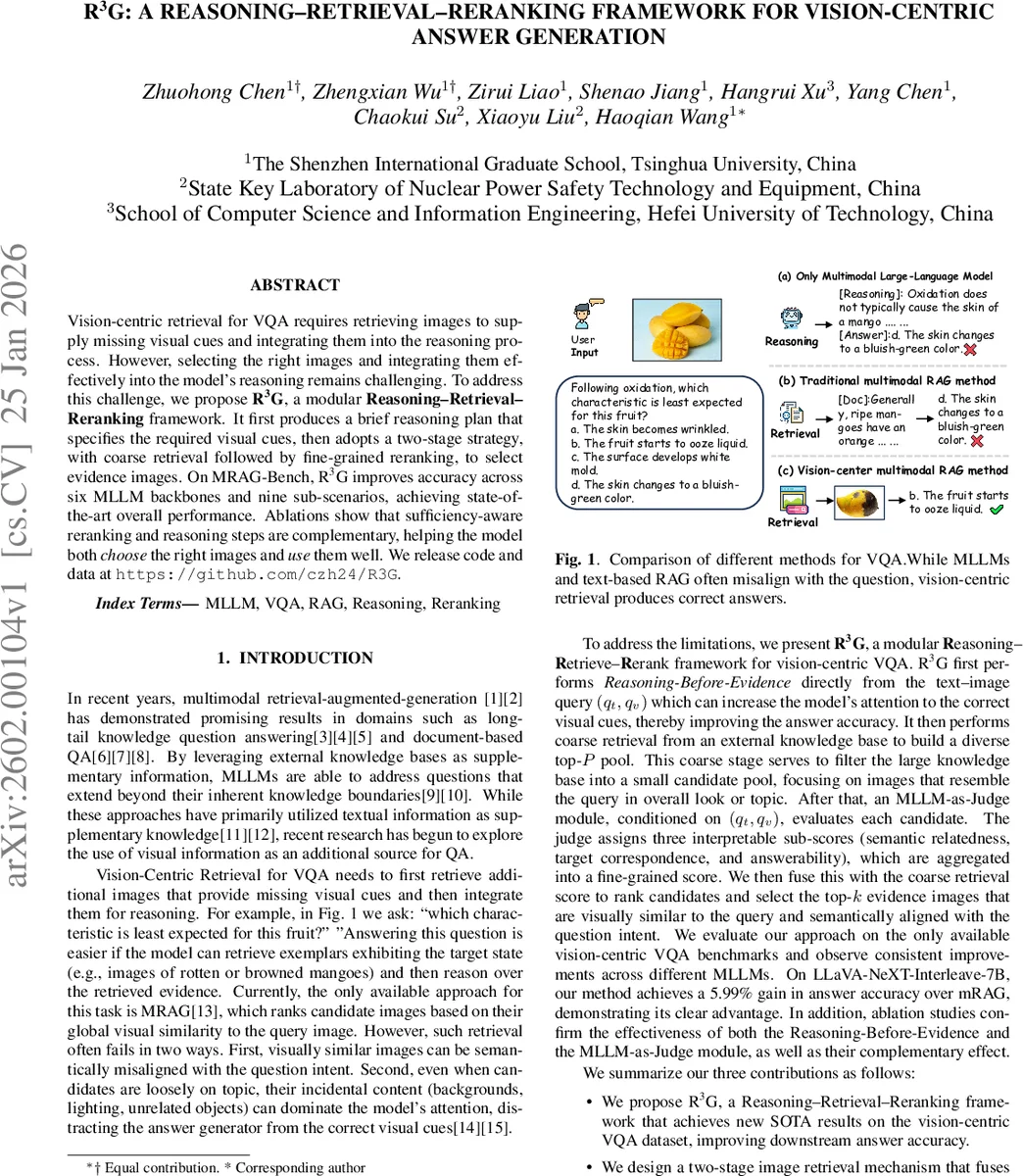
본 논문은 시각‑중심 VQA(Vision‑Centric Question Answering)에서 “어떤 시각적 단서가 부족한가”를 명시적으로 파악한 뒤, 해당 단서를 보완할 외부 이미지를 효율적으로 검색·선별하는 R3G(Reasoning‑Retrieval‑Reranking) 프레임워크를 제안한다. 핵심 아이디어는 세 단계로 구성된다. 첫 번째 단계인 Reasoning‑Before‑Evidence는 질문 텍스트(q_t)와 질의 이미지(q_v)만을 입력으로 하여, 모델이 “어떤 시각적 요소를 확인해야 하는가”를 한 줄 혹은 여러 줄의 계획(R*) 형태로 출력하도록 한다. 이는 이후 검색 단계에서 불필요하거나 오해를 일으킬 수 있는 이미지가 모델의 추론 흐름을 방해하는 것을 방지한다.
두 번째 단계는 Coarse Retrieval이다. CLIP‑ 기반 비전 인코더를 이용해 q_v와 대규모 이미지 지식베이스 D의 모든 이미지 I_i를 임베딩하고, 코사인 유사도 s_img(q_v, I_i)로 정렬한다. 상위 P개의 후보(C_P)를 선택하고, 온도 파라미터 τ를 적용한 소프트맥스로 정규화해 첫 번째 단계 점수 s_1(i)를 산출한다. 이 단계는 전역적인 시각적 유사성을 기반으로 후보를 빠르게 필터링함으로써 연산 효율성을 확보한다.
세 번째 단계는 MLLM‑as‑Judge 재정렬이다. 여기서는 다중모달 대형 언어 모델(MLLM)을 “판사”로 활용해 각 후보 이미지 I(i)에 대해 (q_t, q_v, I(i))를 입력으로 세 가지 서브스코어를 생성한다: (1) Semantic Relevance(r_i) – 이미지의 주요 의미(카테고리, 장면, 동작 등)가 질문 의도와 일치하는 정도, (2) Target Correspondence(t_i) – 이미지가 질문이 요구하는 구체적 대상(시점, 스케일, 가시성 등)을 정확히 담고 있는지, (3) Answerability(a_i) – 해당 이미지와 원본 이미지가 결합될 때 질문에 대한 명확한 답을 도출할 수 있는지. 각 서브스코어는 0~1 사이의 값으로 정규화되며, 가중치 λ_r=0.20, λ_t=0.35, λ_a=0.45 로 가중합해 최종 정밀 점수 s_2(i)를 만든다.
최종 순위 점수 S(i)=s_1(i)+s_2(i) 로 후보를 재정렬하고, 상위 k개의 이미지(I*)를 선택한다. 선택된 이미지와 최초에 생성된 추론 계획 R를 함께 프롬프트에 삽입해 최종 답변 y를 생성한다. 이렇게 하면 모델이 “잘못된 시각적 잡음”에 휘말리지 않으면서, 필요한 단서를 정확히 활용할 수 있다.
실험은 현재 공개된 유일한 Vision‑Centric VQA 벤치마크인 MRAG‑Bench을 사용했으며, 6가지 MLLM 백본(예: Mantis‑8B‑clip‑llama3, LLaVA‑OneVision, Qwen2.5‑VL 등)과 9개의 서브시나리오(Angle, Partial, Scope, Occlusion, Temporal, Deformation, Incomplete, Biological, Others) 전반에 걸쳐 평가했다. R3G는 모든 백본에서 MRAG 대비 평균 3~6%p의 정확도 향상을 달성했으며, 특히 Perspective 카테고리의 Angle·Partial·Occlusion, Transformative 카테고리의 Deformation·Incomplete에서 두드러진 개선을 보였다. 재정렬 단계에서 Recall@K도 크게 상승했으며(예: R@1 33.12→37.86), 이는 선택된 증거 이미지가 실제 정답에 더 가깝다는 것을 의미한다.
Ablation 실험에서는 (1) Coarse Pool 크기(p)와 재정렬 이미지 수(k)의 민감도, (2) Reasoning‑Before‑Evidence 단계의 유무, (3) 재정렬 서브스코어 구성의 효과를 분석했다. p를 5로 늘리면 전체 정확도가 최고(55.14%)에 도달했으며, k를 과도하게 늘리면 오히려 노이즈가 섞여 성능이 감소한다는 점을 확인했다. 또한 Reasoning‑Before‑Evidence 없이 바로 이미지 증거를 투입하면 성능이 평균 2~3%p 감소한다는 결과가 나왔다.
이 논문은 시각‑중심 QA에서 “어떤 시각적 정보가 부족한가”를 명시적으로 모델링하고, 두 단계 검색·재정렬을 통해 효율적이고 정확한 증거 선택을 구현한 점에서 의미가 크다. 특히 MLLM을 판사 역할로 활용해 인간이 정의한 평가 기준을 자연어 형태로 전달함으로써, 기존의 단순 시각 유사도 기반 검색의 한계를 극복했다. 향후 연구는 (i) 텍스트 기반 외부 지식과의 멀티모달 융합, (ii) 동적 가중치 학습을 통한 서브스코어 자동 최적화, (iii) 대규모 실시간 이미지 데이터베이스와의 연동 등을 통해 R3G를 더욱 확장할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기