신뢰성 강화와 추론 능력 향상을 위한 신뢰도 기반 강화 파인튜닝
초록
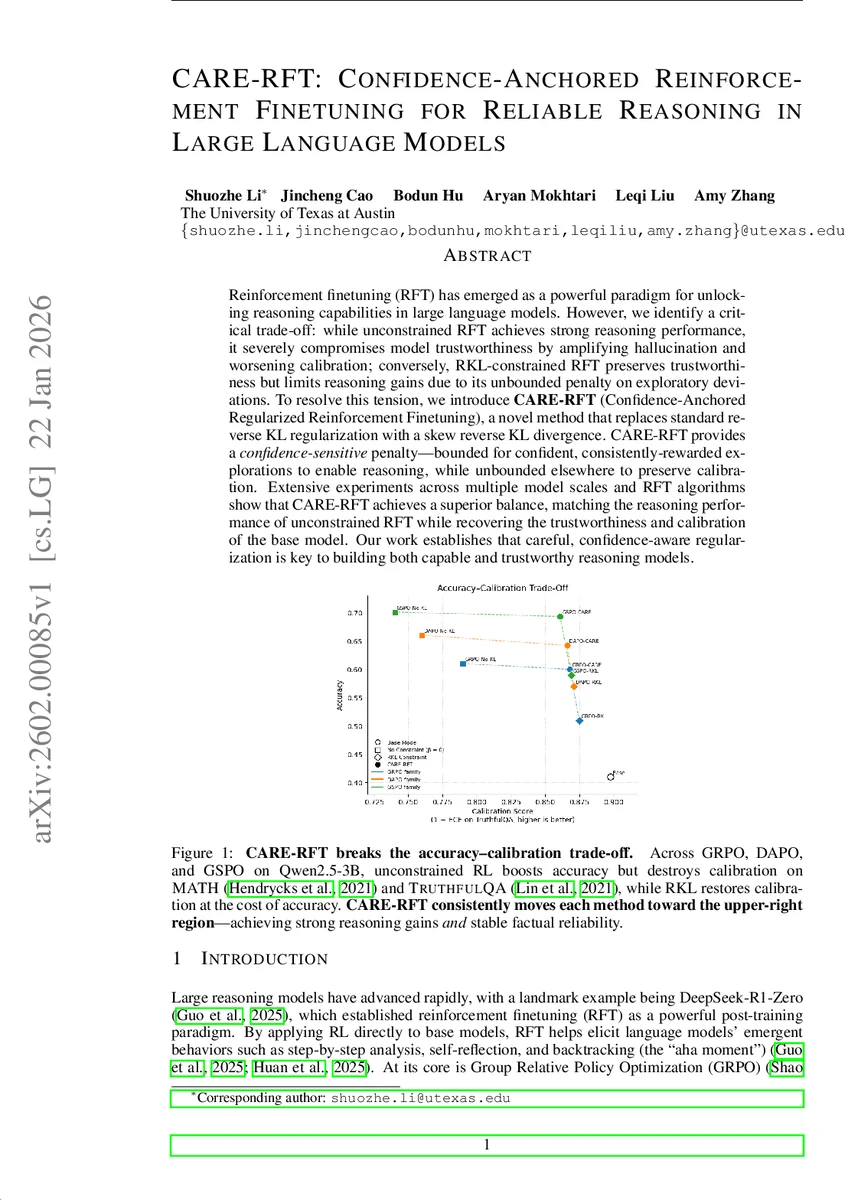
본 논문은 대형 언어 모델의 강화 파인튜닝(RFT)에서 발생하는 추론 성능 향상과 신뢰성(환각·캘리브레이션) 저하 사이의 트레이드오프를 해결한다. 기존 RKL 제약은 탐색을 억제해 추론 개선을 방해하고, 제약 없이 학습하면 환각이 급증한다. 저자들은 이를 보완하기 위해 ‘스큐 리버스 KL(SRKL)’을 도입한 CARE‑RFT를 제안하고, 다양한 모델·스케일에서 정확도와 ECE를 동시에 개선함을 실증한다.
상세 분석
CARE‑RFT의 핵심 아이디어는 “신뢰도‑앵커링”이다. 강화 파인튜닝 과정에서 토큰‑레벨 정규화가 필요하다는 점을 강조하고, 기존 역 KL(RKL) 정규화가 갖는 무한대 페널티가 탐색을 과도하게 억제한다는 한계를 지적한다. RKL은 π_ref가 낮은 확률을 할당한 토큰에 대해 π_θ가 어느 정도 확률을 유지하더라도 로그 비율이 급격히 커져 그래디언트가 무한대로 발산한다. 이는 모델이 새로운 추론 경로를 탐색하려 할 때 즉시 제약에 의해 억제되는 현상으로, 결과적으로 추론 정확도 향상이 제한된다.
이에 대한 해결책으로 저자들은 Lee(2001)의 스큐 리버스 KL(SRKL)을 차용한다. SRKL은 π_ref와 π_θ의 혼합 분포(α·π_θ + (1‑α)·π_ref)를 기준으로 KL을 계산한다. α가 0에 가까우면 기존 RKL과 동일하게 동작하고, α가 1에 가까우면 정규화 효과가 사라져 자유로운 탐색이 가능해진다. CARE‑RFT는 α를 모델의 자체 신뢰도에 따라 동적으로 조정한다. 구체적으로, 토큰이 높은 확신(confidence)과 일관된 보상을 받을 경우(즉, π_θ(o_t|·)가 크게 상승하고 보상이 긍정적일 때) α를 크게 잡아 정규화 강도를 완화한다. 반대로, 모델이 불확실하거나 보상이 부정적일 때는 α를 작게 유지해 RKL과 유사한 강한 제약을 가한다. 이렇게 하면 “신뢰도‑앵커링”이라는 두 가지 목표를 동시에 달성한다.
실험 설계는 크게 세 부분으로 나뉜다. 첫째, GRPO 기반 RFT에서 +Reward, –Reward, Full 업데이트를 각각 수행해 무제한 RFT와 RKL‑제약 RFT가 초래하는 두 가지 실패 모드(과도한 강화에 의한 과신, 무차별적 페널티에 의한 망각)를 정량화한다. 둘째, 다양한 모델 규모(Qwen2.5‑3B 등)와 여러 RFT 변형(GRPO, DAPO, GSPO)에서 CARE‑RFT와 기존 방법을 비교한다. 셋째, 정확도(예: MATH, GSM‑8K)와 사실성(TruthfulQA)뿐 아니라 Expected Calibration Error(ECE)를 동시에 측정해 신뢰성‑추론 트레이드오프를 시각화한다.
결과는 일관되다. CARE‑RFT는 무제한 RFT와 동등하거나 약간 높은 추론 정확도를 유지하면서, RKL‑제약 모델 수준의 낮은 ECE와 높은 사실성 점수를 달성한다. 특히, α를 동적으로 조정한 SRKL이 “신뢰도‑민감” 페널티를 제공해, 모델이 자신 있게 생성한 토큰에 대해서는 자유롭게 확률을 올리고, 불확실한 영역에서는 기존 베이스 모델의 캘리브레이션을 그대로 보존한다는 점이 핵심이다. 이 접근법은 기존 RKL이 가진 “탐색 억제” 문제를 근본적으로 해결하면서도, 토큰‑레벨 정규화가 제공하는 “과도한 강화 억제” 효과는 유지한다.
이 논문은 강화 파인튜닝에서 정규화 전략을 단순히 고정된 KL 형태로 두는 것이 아니라, 모델 자체의 신뢰도와 보상 신호에 따라 가변적으로 조정해야 함을 실증적으로 보여준다. 향후 고신뢰도 AI 시스템 구축에 있어, “신뢰도‑앵커링” 정규화는 추론 능력과 사실성·캘리브레이션을 동시에 최적화하는 강력한 설계 원칙이 될 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기