관계 학습 기반 약물 상호작용 예측 새로운 패러다임
초록
본 논문은 기존의 분자‑중심 DDI 모델이 임베딩 거리와 상호작용 라벨 사이에 일관된 관계를 보이지 않아 일반화에 한계가 있음을 실증한다. 이를 극복하기 위해 약물 정체성을 배제하고 상호작용 자체를 표현하는 관계‑학습 프레임워크 GenRel‑DDI를 제안한다. 사전학습된 분자 인코더를 고정하고, 파트너‑조건화된 관계 트렁크와 어댑터를 통해 관계 표현을 학습함으로써, 보지 못한 약물이나 새로운 약물쌍에 대해 뛰어난 예측 성능을 달성한다. 다양한 벤치마크에서 엔터티‑디스조인트 평가까지 일관된 향상을 보이며, 코드가 공개되어 재현 가능성을 확보한다.
상세 분석
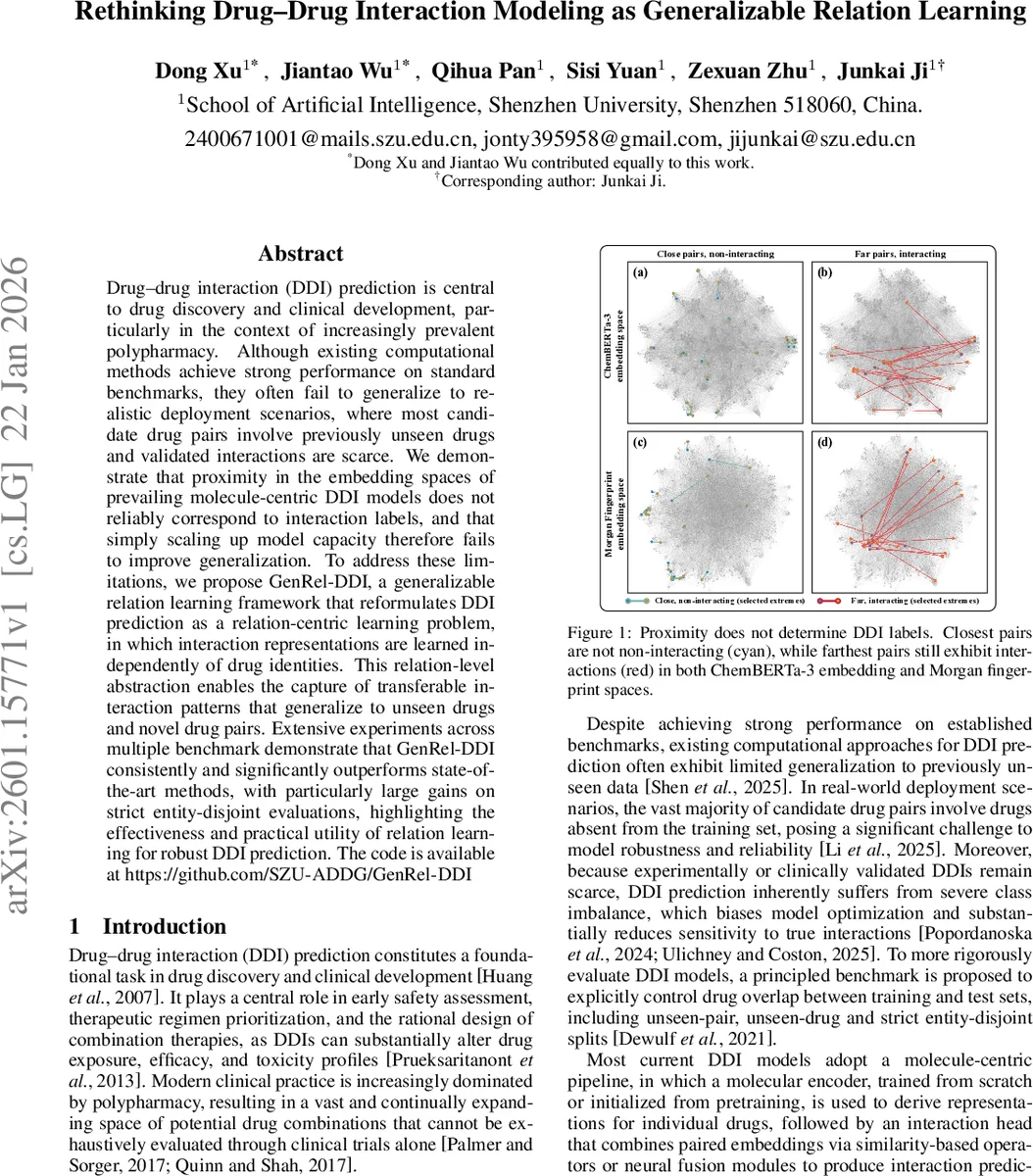
GenRel‑DDI는 기존 DDI 예측 파이프라인의 근본적인 설계 가정을 뒤집는다. 기존 모델은 각 약물을 독립적으로 임베딩한 뒤, 유사도 기반 연산이나 피처 융합 모듈을 통해 상호작용을 추론한다. 그러나 논문은 ChemBERTa‑3와 Morgan Fingerprint 공간에서 가장 가까운 쌍이 비상호작용일 수도, 가장 먼 쌍이 상호작용일 수도 있음을 시각적으로 보여주며, 임베딩 거리와 라벨 사이의 상관관계가 약함을 증명한다. 따라서 모델 용량을 확대해도 일반화 성능이 개선되지 않는다.
GenRel‑DDI는 이 문제를 “관계‑중심” 학습으로 재구성한다. 먼저 다중 사전학습 분자 인코더(그래프, 언어 등)를 고정(앵커)하고, 각 약물에 대해 두 종류의 토큰 스트림(레퍼런스와 어댑티브)을 생성한다. Within‑Drug Conditioning 단계에서 교차‑어텐션을 이용해 레퍼런스와 어댑티브 토큰을 파트너‑조건화하여 하나의 약물 레벨 표현을 만든다. 이후 Role‑Separated Relation Trunk에서 두 약물의 조건화된 토큰 시퀀스를 교차‑어텐션으로 연결해 파트너‑조건화된 상호작용 팩터를 추출하고, 풀링을 통해 최종 관계 벡터 zₐb를 얻는다. 이 관계 벡터는 약물 정체성과 무관하게 학습되므로, 훈련에 등장하지 않은 약물이나 전혀 새로운 쌍에도 동일한 트렁크를 재사용할 수 있다.
이론적으로는 고정된 앵커 스트림이 예측 드리프트를 제한한다는 Lipschitz 기반 증명을 제공한다. 선택적 프리징을 통해 사전학습된 표현은 변하지 않으며, 오직 어댑티브 스트림만이 학습되어 파라미터 효율성을 높인다. 실험에서는 unseen‑pair, unseen‑drug, entity‑disjoint 세 가지 엄격한 데이터 분할에서 기존 최첨단 모델(DDeepDDI, DeepC, GraphDTA 등)을 크게 앞선다. 특히 엔터티‑디스조인트 상황에서 AUPR, AUROC 모두 5~10%p 이상 상승했으며, 이는 관계‑학습이 약물 정체성 의존성을 최소화하고 진정한 상호작용 패턴을 포착함을 의미한다.
또한, 멀티모달(그래프·언어) 인코더를 동시에 활용하면서도 파라미터 공유와 어댑터 설계 덕분에 학습 안정성이 향상되고, 대규모 사전학습 모델을 그대로 활용할 수 있다. 코드 공개와 상세한 재현 실험은 연구 투명성을 높이며, 실제 임상·약물 개발 파이프라인에 바로 적용 가능한 실용성을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기