시각 자동회귀 생성의 미래를 보는 방법, Mirai
초록
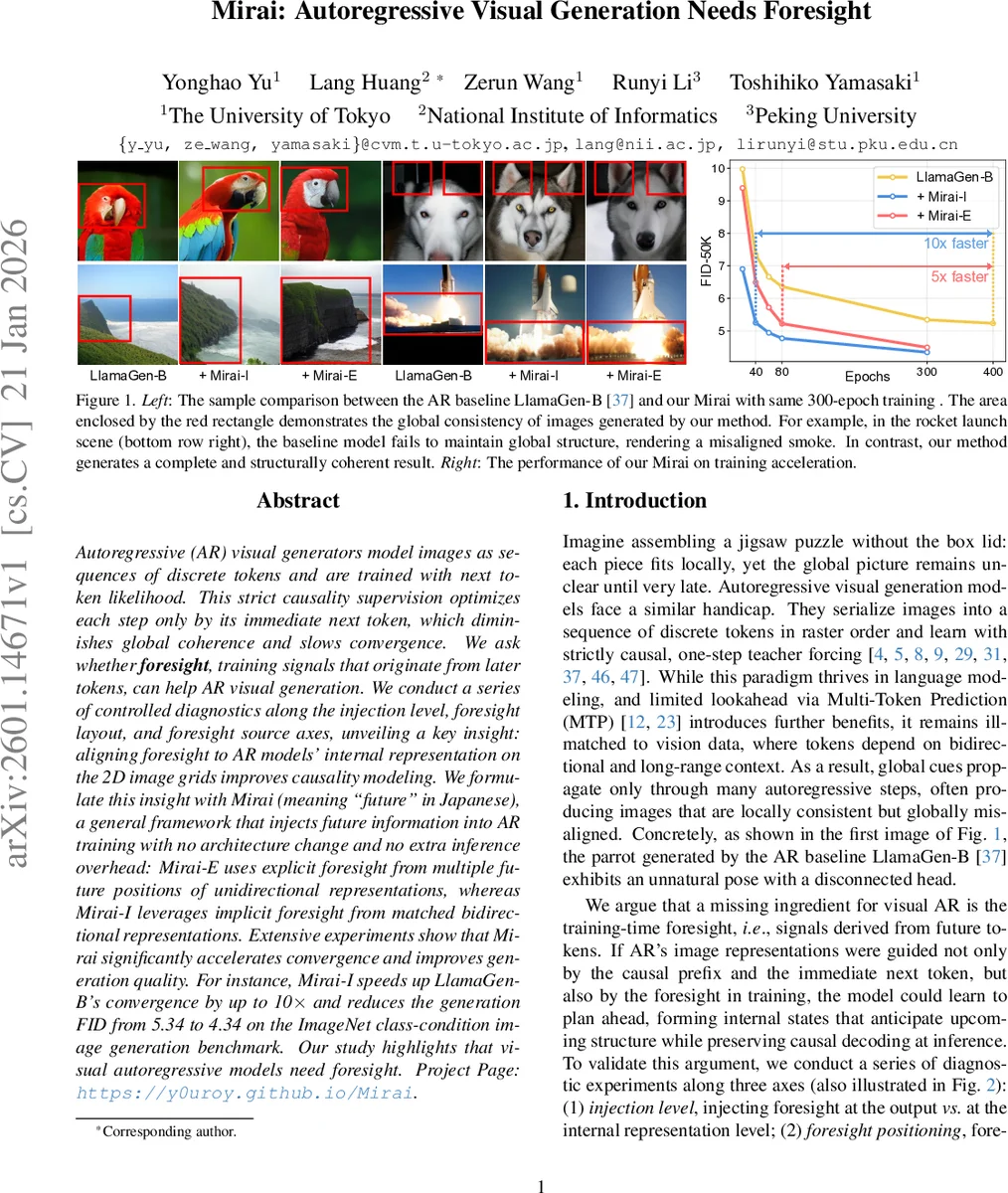
본 논문은 이미지 토큰을 순차적으로 예측하는 자동회귀(AR) 모델이 미래 토큰으로부터 얻는 ‘전망(foresight)’ 정보를 학습에 활용하면 전역 일관성이 향상되고 수렴 속도가 크게 빨라진다는 점을 실증한다. 저자는 두 가지 구현인 Mirai‑E(명시적 전망)와 Mirai‑I(암시적 전망)를 제안하고, 이를 LlamaGen‑B에 적용해 FID를 5.34→4.34까지 낮추고 학습을 최대 10배 가속한다는 결과를 제시한다.
상세 분석
자동회귀 시각 생성 모델은 이미지를 2‑D 격자상의 토큰 시퀀스로 변환하고, 각 단계에서 바로 다음 토큰만을 예측하도록 학습한다(NTP 손실). 이러한 ‘순수 인과성’ 감독은 각 단계가 미래의 전역 구조를 직접 인식하지 못하게 만들며, 결과적으로 지역적으로는 일관되지만 전체 이미지의 형태가 흐트러지는 현상이 빈번히 발생한다. 저자는 이러한 한계를 극복하기 위해 ‘전망(foresight)’이라는 개념을 도입한다. 전망은 현재 위치 n 의 숨겨진 상태 hₙ 가 미래 토큰 xₙ₊ₖ 또는 미래‑인식 특징 fₙₖ 와 정렬되도록 하는 추가 손실 L₍foresight₎를 의미한다.
실험 설계는 세 축(삽입 레벨, 전망 배치, 전망 소스)으로 구분된다. 첫째, 전망을 출력 레이어에 직접 예측하도록 하면 다중 토큰 예측(MTP)과 동일한 경쟁적 그래디언트가 발생해 성능이 저하된다. 반면, 내부 레이어(중간 표현)와 정렬하면 토큰 자체를 예측하지 않으면서도 미래 정보를 은닉 상태에 주입할 수 있어 학습이 안정된다. 둘째, 1‑D(스캔 순서) 대비 2‑D(공간 근접) 배치를 비교했을 때, 2‑D 배치가 이미지의 기하학적 연관성을 보존하므로 FID가 지속적으로 낮아진다. 셋째, 전망 소스로는 (a) 현재 AR 모델의 EMA(Exponential Moving Average)를 이용한 명시적 전망(Mirai‑E)과 (b) 사전 학습된 양방향 비전 인코더(DINOv2 등)를 이용한 암시적 전망(Mirai‑I) 두 가지를 검증한다. EMA 기반 전망은 위치‑인덱싱된 K개의 근접 토큰을 제공해 명시적으로 “앞을 본다”는 신호를 주며, 양방향 인코더는 전체 이미지 컨텍스트를 내재한 특징을 제공해 전역 일관성을 강화한다.
두 방법 모두 학습 단계에서만 사용되며, 추론 시에는 정렬용 프로젝션 헤드와 전망 인코더를 제거해 기존 AR 디코더와 동일한 연산 비용을 유지한다. 실험 결과 LlamaGen‑B에 Mirai‑I를 적용하면 80 epoch 훈련 시 FID가 5.34→4.34로 개선되고, 300 epoch 전체 훈련에서는 수렴 속도가 5‑10배 가속된다. 또한, 내부 레이어 정렬 위치를 4~6번째 레이어에 두면 가장 큰 성능 향상이 관찰된다.
핵심 인사이트는 “전망을 2‑D 격자상의 내부 표현에 정렬하면 인과성 학습이 강화돼 전역 구조를 미리 계획하게 된다”는 점이다. 이는 기존 AR 모델이 ‘앞을 보지 못한다’는 근본적 한계를 데이터‑레벨에서 보완하는 새로운 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기