멀티모달 확산 모델과 자동회귀 VLM의 임베딩 성능 비교 분석
초록
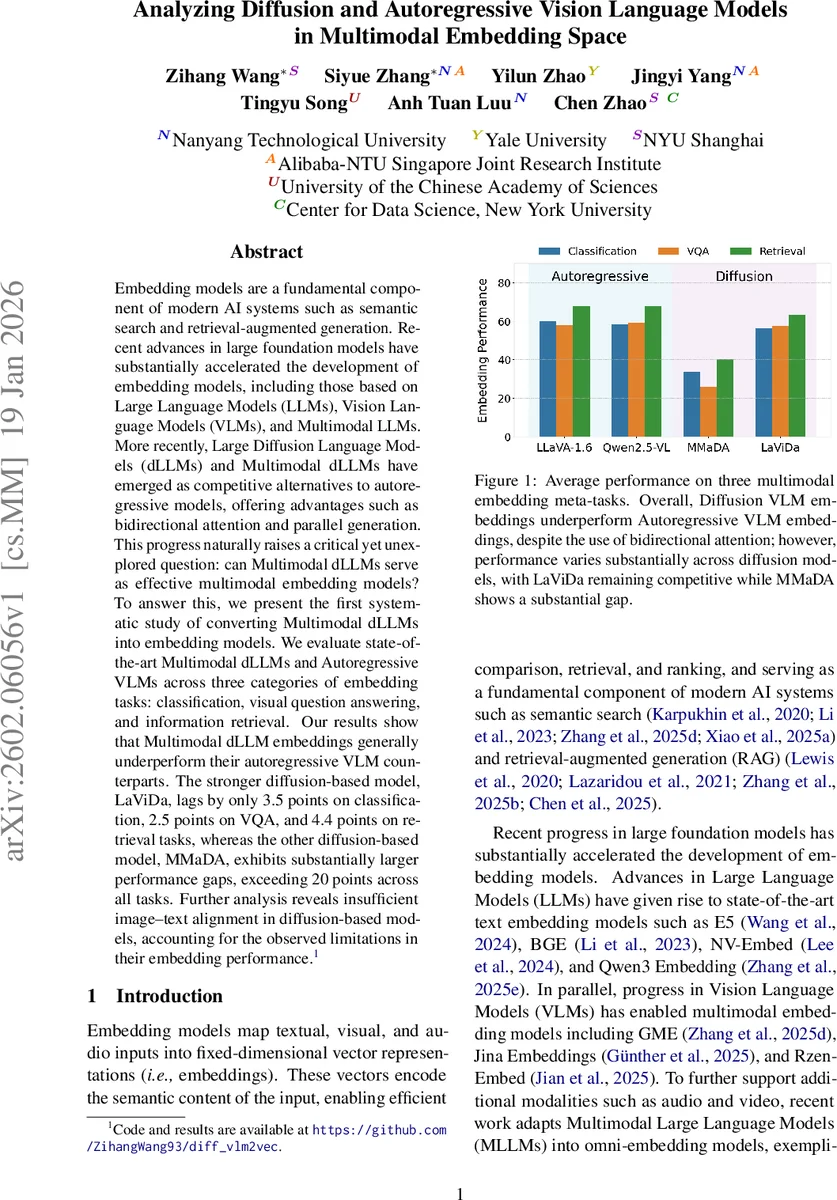
본 논문은 최신 멀티모달 확산 언어 모델(LaViDa, MMaDA)과 자동회귀 비전‑언어 모델(LLaVA‑1.6, Qwen2.5‑VL)을 동일한 대비 학습 파이프라인에 적용해 임베딩 성능을 평가한다. 32개 데이터셋(분류·VQA·검색)에서 LaViDa는 자동회귀 모델에 비해 평균 3‑5점 정도만 뒤처지는 반면, MMaDA는 20점 이상 크게 뒤처진다. 분석 결과는 확산 모델이 이미지‑텍스트 정렬이 부족해 임베딩 품질이 낮아진다는 점을 보여준다.
상세 분석
이 연구는 멀티모달 확산 언어 모델(dLLM)과 전통적인 자동회귀 VLM을 동일한 대비 학습(contrastive fine‑tuning) 환경에 두고, 임베딩 벡터를 추출해 3가지 메타‑태스크(분류, 시각질문응답(VQA), 정보검색)에서 성능을 정량적으로 비교한다.
1️⃣ 모델 구조 차이: 자동회귀 VLM은 인코더‑디코더가 아닌 순방향(causal) 어텐션을 사용해 다음 토큰을 예측한다. 반면 확산 VLM은 토큰 마스킹·복원 과정을 통해 양방향 어텐션을 적용한다. 임베딩 추출 방식도 다르게 설계했는데, 자동회귀 모델은 마지막 토큰을, 확산 모델은 전체 토큰에 평균 풀링(mean‑pooling)을 적용한다. 이러한 차이는 양쪽 모델이 사전학습 시 학습한 토큰 상호작용 패턴을 그대로 유지하게 만든다.
2️⃣ 대비 학습 설계: 논문은 VLM2Vec 방식을 차용해 InfoNCE 손실을 사용, 이미지‑텍스트 쌍을 양성 샘플, 배치 내·외부 하드 네거티브를 음성 샘플로 삼았다. 동일한 학습률·배치 크기·에폭 수를 적용해 공정성을 확보했으며, 제한된 라벨 데이터(수천 개)와 대규모 라벨(수십만 개) 두 조건에서 성능 변화를 관찰했다.
3️⃣ 실험 결과:
- 분류: LaViDa는 자동회귀 모델 대비 평균 3.5점(전체 59.7→56.2)만 감소했으며, 특히 ImageNet‑1K, VOC2007 등 대규모 이미지 분류에서 경쟁력을 유지했다. 반면 MMaDA는 20점 이상(68.9→27.0) 급락, 특히 이미지‑텍스트 정렬이 중요한 데이터셋에서 큰 격차를 보였다.
- VQA: LaViDa는 OK‑VQA·DocVQA·ScienceQA 등에서 2‑5점 차이로 자동회귀 모델에 근접했지만, MMaDA는 전반적으로 20점 이상 낮았다. 이는 질문‑답변 과정에서 이미지‑텍스트 연관성을 정확히 포착하지 못함을 의미한다.
- 검색: FashionIQ·CIRR·VisualNews 등 멀티모달 검색에서도 LaViDa는 4.4점 정도만 뒤처졌고, MMaDA는 15‑30점 차이를 보였다. 특히 지시어 기반 이미지 변형 검색에서 MMaDA는 이미지‑텍스트 정렬 부족으로 목표 이미지와의 유사도 점수가 크게 낮았다.
4️⃣ 정렬 부족 원인: 저자는 두 가지 정량적 분석을 제시한다. 첫째, 이미지‑텍스트 쌍의 코사인 유사도가 자동회귀 모델보다 현저히 낮았다(평균 0.42→0.31). 둘째, 사전학습 시 이미지 토크나이저(VQ‑GAN)와 텍스트 토크나이저가 동일한 토큰 공간을 공유하지 않아, 디퓨전 과정에서 이미지 토큰이 텍스트 토큰에 비해 상대적으로 약한 신호를 제공한다. 결과적으로 디퓨전 모델은 “양방향 어텐션”이라는 이점을 살리지 못하고, 이미지‑텍스트 정렬이 약한 상태에서 임베딩을 생성한다.
5️⃣ 파인‑튜닝 데이터 효율성: 자동회귀 VLM은 1k5k 라벨만으로도 성능이 급격히 상승하는 반면, 확산 VLM은 10k50k 라벨이 필요했으며, 라벨이 늘어나도 수렴 속도가 느렸다. 이는 양방향 어텐션이 전역 컨텍스트를 잘 포착하지만, 정렬된 멀티모달 신호가 부족하면 학습 효율이 저하된다는 점을 시사한다.
6️⃣ 시사점: 현재 가장 강력한 멀티모달 임베딩은 자동회귀 백본을 갖는 VLM이며, 확산 기반 모델은 아직 이미지‑텍스트 정렬을 강화하는 전용 사전학습 전략이 필요하다. LaViDa와 같이 비전 인코더와 언어 디코더를 별도로 연결하고, 이미지 토큰을 텍스트 토큰과 명시적으로 매핑하는 설계가 성능 격차를 줄이는 핵심 요인으로 보인다.
댓글 및 학술 토론
Loading comments...
의견 남기기