iReasoner: 자기 진화 멀티모달 모델을 위한 단계‑인식 추론 보상
초록
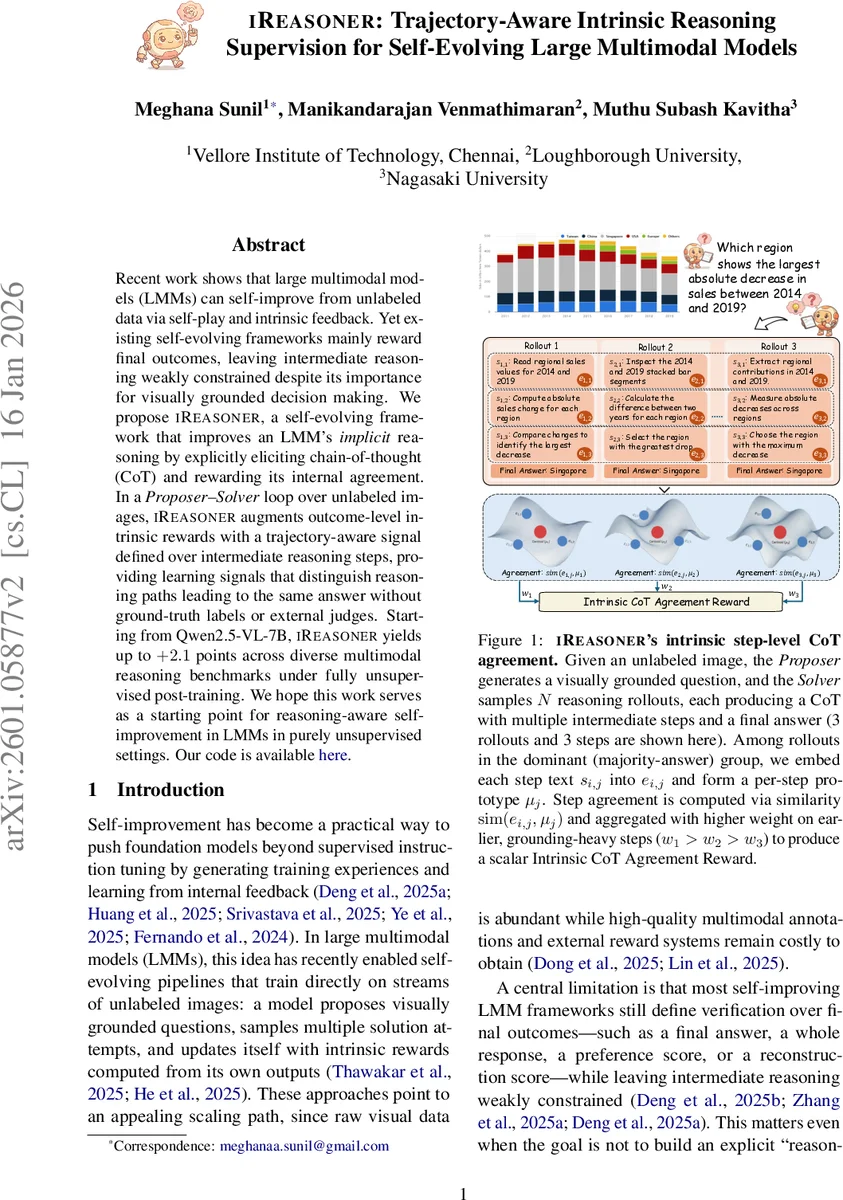
iReasoner는 라벨이 없는 이미지 데이터를 활용해 대규모 멀티모달 모델을 스스로 개선하는 프레임워크이다. 기존의 자기‑진화 방식이 최종 정답에만 보상을 주는 데 반해, 본 연구는 체인‑오브‑쓰(Chain‑of‑Thought, CoT) 단계별 일치를 내부 보상으로 도입한다. Proposer‑Solver 루프에서 Solver가 여러 추론 롤아웃을 생성하고, 동일한 정답을 낸 롤아웃들의 각 단계를 임베딩해 평균 프로토타입을 만든 뒤, 코사인 유사도로 단계별 일치를 측정한다. 이 ‘Intrinsic CoT Agreement Reward’를 정답‑레벨 자기‑일관성 보상과 가중합해 정책 그래디언트 업데이트에 사용한다. Qwen2.5‑VL‑7B를 초기 모델로 실험했을 때, 완전 무감독 사후 학습만으로도 다양한 멀티모달 추론 벤치마크에서 평균 +2.1 점의 성능 향상을 달성했다.
상세 분석
iReasoner는 라벨이 전혀 없는 이미지 스트림 위에서 LMM을 자기‑진화시키는 기존 프레임워크(EvoLMM, VisPlay 등)의 한계를 정확히 짚는다. 기존 방법은 ‘답변 일관성’이나 ‘답변 자체 점수’에만 의존해, 동일한 정답을 도출했더라도 전혀 다른 중간 추론 과정을 구분하지 못한다는 문제를 제기한다. 이 문제를 해결하기 위해 저자는 Solver가 N개의 CoT 롤아웃을 생성하도록 설계하고, 정답이 가장 많이 선택된 ‘지배 답변 그룹’ 내에서 각 단계별 텍스트를 모델 내부 임베딩 f(·)으로 변환한다. 이후 같은 단계 인덱스 j에 대해 평균 프로토타입 µ_j를 계산하고, 개별 롤아웃 단계 e_i,j와의 코사인 유사도 r_i,j를 구한다. 초기 단계에 높은 가중치 w_1 > w_2 > … 를 적용해 ‘시각적 근거가 강한 초기 단계’를 더 강조한다. 최종 ‘Intrinsic CoT Agreement Reward’는 단계 유사도와 지배 그룹의 밀도 ρ (=|G|/N) 를 곱해 정의되며, 이는 라벨이 없어도 자연스럽게 ‘합리적 추론 경로’를 선호하도록 만든다. Solver의 전체 보상 r_sol_i는 정답‑레벨 자기‑일관성 보상 r_ans_i와 단계‑레벨 보상 r_step_i를 λ(t) 라는 시간‑가변 가중치로 혼합한다. λ(t)는 학습 초기에 낮게 시작해 점진적으로 상승해, 초기에는 정답 일관성에, 이후에는 단계 일치에 더 큰 비중을 두게 한다. 이러한 설계는 학습이 진행됨에 따라 지배 답변 그룹이 안정화되고, 단계별 프로토타입이 의미 있게 형성되는 것을 실험적으로 확인한다(그룹 크기와 평균 유사도 모두 상승). 결과적으로 iReasoner는 기존 자기‑진화 파이프라인에 비해 중간 추론을 명시적으로 제어함으로써, 동일 정답이라도 비합리적 경로를 억제하고, 전반적인 추론 정확도와 신뢰성을 동시에 끌어올린다.
댓글 및 학술 토론
Loading comments...
의견 남기기