예측 엔트로피 기반 자동 프롬프트 가중치 부여
초록
본 논문은 오디오‑언어 모델의 제로샷 분류에서 텍스트 프롬프트에 따른 성능 변동성을 최소화하기 위해, 예측 엔트로피를 최소화하는 프롬프트 가중치 최적화 기법을 제안한다. 라벨 없이 배치 전체 혹은 개별 샘플에 적용 가능하며, 5개의 벤치마크 데이터셋에서 기존 다수결·임베딩 평균 앙상블 대비 평균 0.7~1.4%의 정확도 향상을 달성한다.
상세 분석
이 연구는 최근 주목받는 오디오‑언어 모델(ALM), 특히 CLAP‑2022를 기반으로 제로샷 오디오 분류 시 텍스트 프롬프트 선택에 따른 성능 편차가 심각한 문제임을 지적한다. 기존 접근법은 프롬프트 학습(라벨 필요)이나 단순 앙상블(모든 프롬프트를 동일 가중치)으로, 전자는 비용이 크고 후자는 성능 저하를 일으키는 ‘노이즈 프롬프트’를 배제하지 못한다. 저자들은 프롬프트 가중치를 확률 단순체 상의 변수 β로 정의하고, 전체 샘플에 대한 예측 확률 p_i의 엔트로피 평균을 최소화하는 목적함수 L(β)를 설계한다. L(β)는 (i) 예측 엔트로피 최소화, (ii) 초기 제로샷 예측 ˆp와의 KL 발산을 통한 정규화, (iii) β 자체의 엔트로피를 억제하는 세 항으로 구성된다. 특히 (ii) 항은 라벨이 없는 상황에서도 기존 단일 프롬프트(“This is a sound of {class}”)의 예측을 기준으로 과도한 편향을 방지한다. 최적화는 고정점 업데이트식 β_j ∝ exp(R_j/λ_β) 로 수행되며, R_j는 각 프롬프트가 전체 샘플에 미치는 엔트로피·정규화 기여를 합산한 값이다.
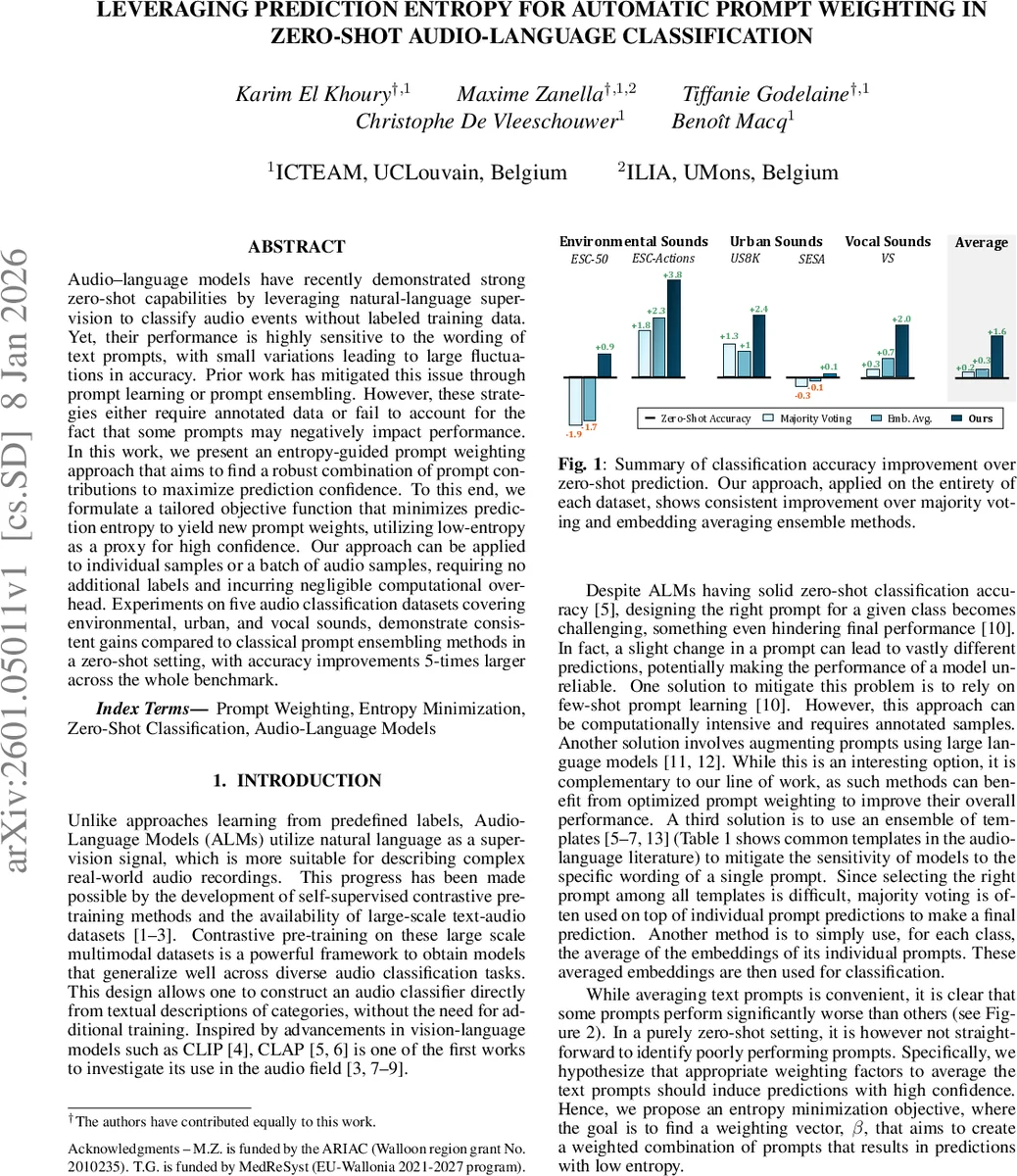
실험은 35개의 손수 만든 프롬프트 템플릿을 사용해 ESC‑50, ESC‑Actions, US8K, SESA, VS 등 5개 데이터셋에서 평가한다. 두 가지 가중치 학습 시나리오가 제시된다. (1) Single‑sample β: 각 샘플당 독립적으로 β를 최적화, 라벨이 전혀 없는 상황에서도 평균 0.7% 정확도 향상. (2) Dataset β: 전체 데이터셋을 이용해 하나의 공통 β를 학습, 추가 정규화 λ_zs를 낮춰 성능을 0.9% 정도 더 끌어올림. 마지막으로 프롬프트 프루닝을 순환적으로 적용해 약 50%의 저성능 프롬프트를 제거하고 재학습함으로써 전체 평균 1.4%의 추가 이득을 얻는다.
비교 대상인 다수결, 엔트로피 가중 다수결, 임베딩 평균, 엔트로피 가중 임베딩 평균, 프루닝 기반 방법들과 비교했을 때, 제안 방법은 모든 데이터셋에서 일관적으로 우수함을 보인다. 특히 ESC‑Actions에서는 3.8%p의 큰 개선을 기록한다. 계산 비용 측면에서는 임베딩 추출 외에 추가 연산이 0.2초 수준에 불과해 실용성이 높다.
이 논문의 주요 공헌은 (① 엔트로피를 신뢰도 proxy로 삼아 라벨 없이 프롬프트 가중치를 학습하는 정량적 프레임워크, ② β에 대한 엔트로피 정규화와 제로샷 정규화를 결합해 과적합을 방지, ③ 프루닝 순환을 통한 저품질 프롬프트 자동 제거)이며, 이는 향후 멀티모달 제로샷 시스템에서 프롬프트 설계 비용을 크게 낮출 수 있는 길을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기