음성언어 모델을 위한 의미 확장을 통한 일반화 가능한 프롬프트 튜닝
초록
본 논문은 오디오‑텍스트 멀티모달 모델(ALM)에서 프롬프트 튜닝이 겪는 “Base‑New Tradeoff”(BNT) 문제를 해결하기 위해, 대형 언어 모델(LLM)로부터 생성된 의미적 이웃을 활용해 프롬프트 임베딩 공간을 정규화하는 SEPT(Semantically Expanded Prompt Tuning) 프레임워크를 제안한다. 의미 확장 손실과 마진 제약을 도입해 클래스 내 응집성을 높이고 클래스 간 구분성을 유지함으로써, 기존 프롬프트 튜닝 기법들의 베이스‑뉴 일반화와 데이터셋 간 전이 성능을 일관되게 향상시킨다.
상세 분석
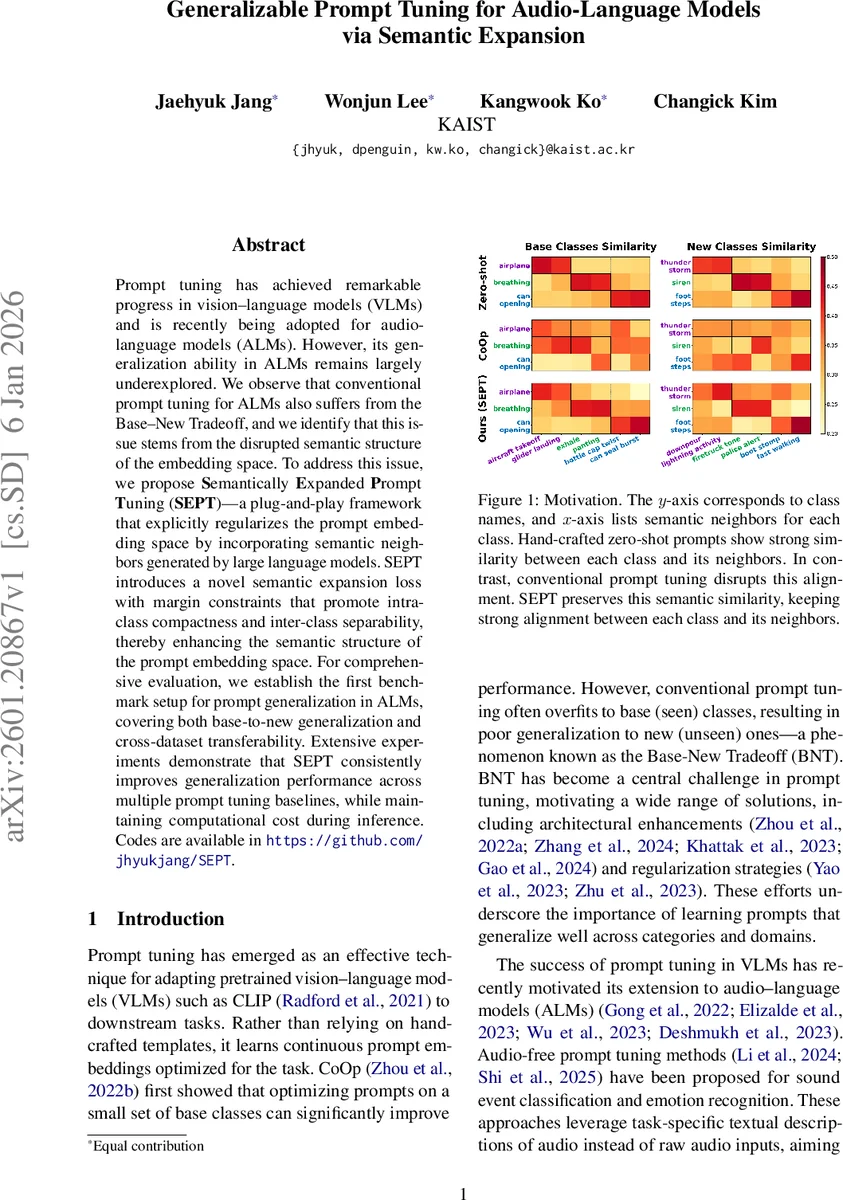
SEPT는 기존 ALM 기반 프롬프트 튜닝이 학습 데이터에만 최적화되어 텍스트 임베딩 공간의 의미적 구조를 파괴한다는 점을 정확히 짚어낸다. 특히 오디오 데이터셋은 클래스 수가 적고 의미적 커버리지가 희박해, 학습된 프롬프트가 서로 격리된 프로토타입으로 전락하기 쉽다. 이를 해결하기 위해 저자들은 각 클래스마다 LLM을 이용해 N개의 의미적 이웃(동의어, 파라프레이즈, 관련 음향 표현 등)을 자동 생성한다. 이렇게 풍부해진 이웃 집합은 원래 클래스 임베딩 주위에 밀집된 의미 클러스터를 형성하도록 유도한다.
핵심 기술은 두 가지 마진 기반 손실이다. L_intra는 클래스 임베딩 z_i와 해당 클래스의 긍정 이웃 p_{n}^{i} 사이 거리가 사전에 정의된 마진 m_{i,i,n}보다 클 경우 패널티를 부여해, 의미적 이웃을 가능한 한 가깝게 끌어당긴다. 반대로 L_inter는 클래스 i의 임베딩이 다른 클래스 j(≠i)의 이웃 p_{n}^{j}와 지나치게 가까워지는 것을 방지한다. 여기서 마진 m_{i,j,n}은 다양한 템플릿 프롬프트(예: “a sound of”, “a recording of”)를 사용해 평균 L2 거리로 사전 계산된다. 이러한 마진 제약은 긍정 이웃을 무조건적으로 겹치게 만들지 않으며, 부정 이웃을 과도하게 멀리 밀어내는 현상을 억제한다.
손실 함수는 기존의 교차 엔트로피 L_ce와 가중치 λ를 곱한 의미 확장 손실 L_se를 합산한 L_total = L_ce + λ·L_se 형태다. 이 설계는 프롬프트 튜닝이 원래의 지도 학습 목표를 유지하면서도 텍스트 임베딩 공간의 구조적 일관성을 보강하도록 만든다.
또한 SEPT는 ‘플러그‑인’ 방식으로 설계돼, CoOp, CoCoOp, Kg‑CoOp 등 기존 프롬프트 튜닝 방법에 그대로 삽입 가능하다. 학습 단계에서만 의미 이웃을 활용하고, 추론 시에는 추가 연산이 없으므로 실시간 응용에 부담을 주지 않는다.
실험에서는 베이스‑뉴 일반화와 교차 데이터셋 전이 두 축을 모두 평가했으며, 6개의 공개 오디오 분류 벤치마크(악기, 음향 장면, 보컬 사운드 등)에서 모든 베이스라인에 대해 평균 2~4%p의 정확도 향상을 기록했다. 특히 클래스 수가 적은 소규모 데이터셋에서 의미 확장이 큰 효과를 보였으며, 마진 파라미터 λ와 N(이웃 수)의 민감도 분석에서도 안정적인 성능 개선을 확인했다.
결과적으로 SEPT는 의미적 구조를 명시적으로 보존·강화함으로써, ALM에서 프롬프트 튜닝이 겪는 과적합과 의미 붕괴 문제를 근본적으로 완화한다는 점에서 중요한 기여를 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기