VLM 평가의 새 기준 DatBench
초록
이 논문은 비전‑언어 모델(VLM)의 평가가 신뢰성, 구별력, 효율성이라는 세 가지 핵심 기준을 만족해야 한다고 주장한다. 기존 다중선택형 벤치마크는 추측을 장려하고 이미지 없이도 답을 맞출 수 있는 ‘블라인드‑솔버블’ 질문이 다수를 차지해 모델의 실제 능력을 과대평가한다. 또한 라벨 오류와 모호한 샘플이 전체 데이터의 20‑40%를 차지한다. 저자들은 이러한 문제를 해결하기 위해 기존 데이터셋을 생성형 과제로 변환하고, 블라인드‑솔버블 및 라벨 오류 샘플을 필터링한다. 정제된 DATBENCH‑FULL(33개 데이터셋)와 경량화된 DATBENCH(속도 13배~50배 향상)를 공개하며, 변환·필터링이 모델 간 구별력을 크게 높이고 평가 비용을 크게 절감함을 실험을 통해 입증한다.
상세 분석
논문은 먼저 VLM 평가가 가져야 할 세 가지 desiderata를 정의한다. 첫째, faithfulness는 평가가 실제 이미지‑텍스트 상호작용을 반영해야 함을 의미한다. 둘째, discriminability는 서로 다른 성능 수준의 모델을 명확히 구분할 수 있어야 한다는 요구다. 셋째, efficiency는 대규모 모델을 평가할 때 계산 비용이 과도하지 않아야 함을 강조한다. 이러한 기준을 바탕으로 기존 벤치마크를 면밀히 분석했을 때, 다중선택형(MCQ) 형식이 가장 큰 문제점을 드러낸다. MCQ는 정답 후보가 제한돼 있기 때문에 모델이 단순히 확률적으로 추측해도 높은 점수를 받을 수 있다. 특히, 이미지 없이도 정답을 유추할 수 있는 ‘blindly‑solvable’ 질문이 전체 데이터의 30‑70%를 차지한다는 통계는 평가의 신뢰성을 크게 훼손한다. 라벨 오류와 모호한 질문도 무시할 수 없으며, 일부 데이터셋에서는 전체 샘플의 42%까지가 잘못 라벨링되었거나 해석이 애매한 것으로 보고되었다. 이러한 결함은 모델이 실제 응용 환경에서 보일 성능을 과대평가하게 만든다.
이를 해결하기 위해 저자들은 두 가지 핵심 전략을 제시한다. 첫째, 전환(transformation) 단계에서 MCQ를 자유형 생성(generative) 과제로 변환한다. 예를 들어, “이 사진에 보이는 물체는 무엇인가?”라는 질문을 “사진을 설명해라” 형태로 바꾸어 모델이 이미지 정보를 직접 활용하도록 강제한다. 실험 결과, 변환 후 동일 모델의 성능이 평균 35% 이상 급락했으며, 이는 기존 MCQ가 모델의 실제 이해 능력을 제대로 측정하지 못했음을 시사한다. 둘째, 필터링(filtering) 단계에서 블라인드‑솔버블 샘플과 라벨 오류 샘플을 자동 및 수동으로 제거한다. 자동 필터링은 텍스트‑전용 모델을 이용해 이미지 없이도 높은 정확도를 보이는 질문을 탐지하고, 라벨 오류는 인간 검증을 통해 정제한다. 이 과정을 거친 데이터셋은 구별력이 크게 향상되었으며, 평가에 필요한 FLOPs가 평균 13배, 최악의 경우 50배까지 감소했다.
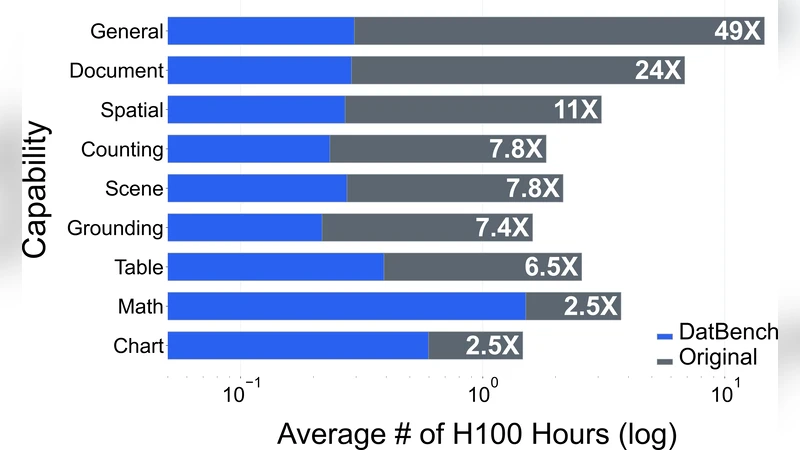
데이터 정제 후 구축된 DATBENCH‑FULL은 33개의 데이터셋을 아우르며, VLM이 보여줄 수 있는 9가지 핵심 능력(객체 인식, 관계 추론, 캡션 생성, 시각적 질문응답 등)을 포괄한다. 또한, 고속 버전인 DATBENCH는 전체 데이터의 10% 정도만 남겨두고도 원본과 거의 동일한 구별력을 유지한다. 이러한 결과는 평가 비용이 급증하는 현재 상황에서 지속 가능한 평가 파이프라인을 제공한다는 점에서 큰 의미가 있다. 논문은 평가 기준을 명확히 정의하고, 기존 벤치마크를 체계적으로 정제함으로써 VLM 연구가 보다 신뢰성 있고 효율적인 방향으로 나아갈 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기