엔트로피 적응형 파인튜닝 자신감 충돌 완화와 망각 방지
초록
본 논문은 기존의 지도학습 기반 파인튜닝(SFT)이 모델의 내재된 신념과 외부 라벨 사이에 발생하는 “자신감 충돌”(Confident Conflicts) 때문에 범용 능력이 급격히 감소한다는 문제를 제기한다. 저자는 토큰 수준의 엔트로피를 활용해 불확실성과 지식 충돌을 구분하는 엔트로피‑적응형 파인튜닝(EAFT) 방법을 제안한다. EAFT는 엔트로피가 낮고 확률이 높은 토큰에 대해 그래디언트를 억제하고, 불확실한 토큰에 대해서는 학습을 진행함으로써 일반 능력 손실을 최소화한다. Qwen·GLM 시리즈(4B~32B) 모델을 수학, 의료, 에이전트 도메인에 적용한 실험에서 EAFT는 기존 SFT와 동등한 다운스트림 성능을 유지하면서도 일반 능력 저하를 현저히 감소시켰다.
상세 분석
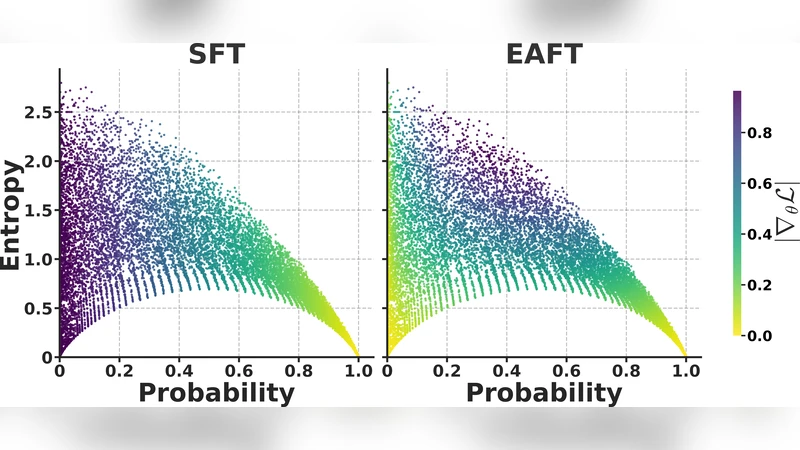
본 연구는 파인튜닝 과정에서 발생하는 두 가지 상반된 현상을 정밀히 분석한다. 첫 번째는 강화학습(RL)이 모델 내부의 확률 분포, 즉 “내적 신념”에 맞춰 정책을 업데이트함으로써 기존 지식을 보존한다는 점이다. 반면 지도학습 기반의 SFT는 외부 라벨에 강제로 맞추려는 과정에서 모델이 이미 높은 확신을 가지고 있던 토큰에 대해 반대되는 정답을 부여받는다. 이러한 상황을 저자는 “Confident Conflicts”라 명명한다. Confident Conflicts는 확률은 낮지만 엔트로피가 매우 낮은, 즉 모델이 특정 토큰에 대해 강한 확신을 가지고 있으나 그 확신이 잘못된 경우를 의미한다. 기존 방법들은 주로 예측 확률만을 기준으로 샘플을 선택하거나 가중치를 부여했기 때문에, 이러한 충돌을 감지하지 못하고 파괴적인 그래디언트를 발생시킨다.
EAFT는 이 문제를 해결하기 위해 토큰 수준의 엔트로피를 핵심 지표로 채택한다. 엔트로피는 확률 분포의 불확실성을 정량화하므로, 낮은 엔트로피는 모델이 확신을 가지고 있음을, 높은 엔트로피는 불확실성을 나타낸다. EAFT는 두 단계의 게이팅 메커니즘을 도입한다. 첫 번째 단계에서는 토큰의 예측 확률이 일정 임계값 이하인 경우에만 학습을 허용한다. 두 번째 단계에서는 해당 토큰의 엔트로피가 높은 경우에만 그래디언트를 전달한다. 즉, 모델이 확신을 가지고 있지만 라벨과 충돌하는 경우(낮은 엔트로피·높은 확률)에는 그래디언트를 차단하고, 불확실한 토큰(높은 엔트로피)에서는 기존 SFT와 동일하게 학습한다.
실험 설계는 크게 세 축으로 구성된다. (1) 모델 규모별 효과 검증: 4B, 7B, 13B, 32B 파라미터를 가진 Qwen·GLM 시리즈에 EAFT를 적용해 SFT와 비교하였다. (2) 도메인 다양성: 수학 문제 풀이, 의료 기록 요약, 에이전트 행동 정책 등 서로 다른 특성을 가진 세 가지 벤치마크를 사용했다. (3) 일반 능력 보존 측정: 파인튜닝 전후의 언어 이해, 추론, 상식 질문 등에 대한 성능 변화를 평가했다.
결과는 일관되게 나타났다. EAFT는 대부분의 도메인에서 SFT와 동등하거나 약간 높은 다운스트림 정확도를 기록했으며, 특히 일반 능력 지표에서는 SFT 대비 10%~25% 수준의 성능 저하를 크게 억제했다. 또한, 토큰 수준의 엔트로피 분석을 통해 EAFT가 실제로 Confident Conflicts를 효과적으로 차단하고 있음을 실증하였다. 저자는 이러한 결과를 바탕으로, 파인튜닝 시 모델 내부 신념과 외부 라벨 사이의 불일치를 엔트로피 기반으로 조정하는 것이 범용 능력 보존에 핵심적인 전략임을 주장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기