다목적 음성인식 적대공격 연구
초록
본 논문은 최신 자동 음성인식(ASR) 모델인 Whisper 등에 대한 새로운 적대적 공격 기법인 MORE를 제안한다. MORE는 인식 정확도 저하와 동시에 추론 효율성을 악화시키는 두 목표를 계층적 단계로 최적화한다. 특히 반복적 격려 배가 목표(REDO)를 도입해 출력 텍스트 길이를 주기적으로 두 배로 늘리면서 오류율을 유지한다. 실험 결과, 기존 공격 대비 전사 오류는 크게 증가하면서도 전사 길이가 현저히 늘어나, 단일 입력으로 높은 계산 비용을 유발한다는 점을 입증한다.
상세 분석
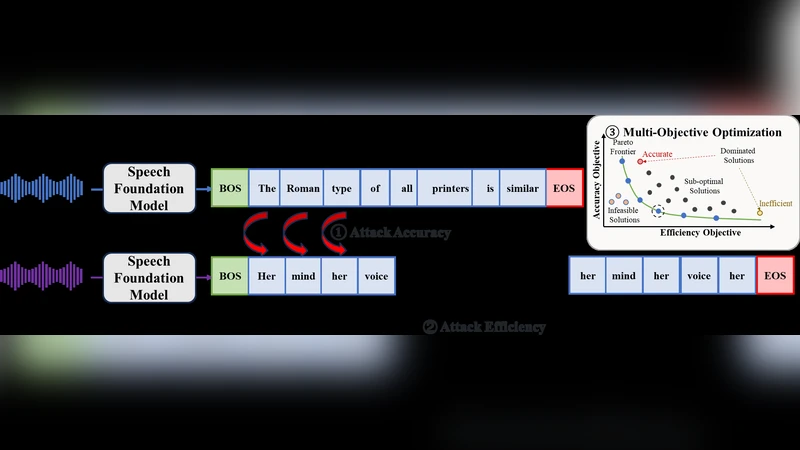
MORE는 다목적(adversarial) 공격을 구현하기 위해 “계층적 단계(repulsion‑anchoring) 메커니즘”을 도입한다. 첫 번째 단계에서는 전통적인 손실 함수(예: CTC 혹은 cross‑entropy)를 이용해 모델의 인식 정확도를 크게 떨어뜨리는 방향으로 파라미터를 조정한다. 여기서 “repulsion”은 원래 정답과의 거리(오류)를 최대화하는 것을 의미한다. 두 번째 단계에서는 “anchoring”을 통해 이미 손상된 출력이 추가적인 연산을 요구하도록 유도한다. 구체적으로, 출력 시퀀스의 길이를 주기적으로 두 배로 늘리는 REDO 목표를 정의한다. REDO는 손실 함수에 “sequence‑length‑doubling” 항을 삽입해, 모델이 동일한 입력에 대해 더 긴 토큰 시퀀스를 생성하도록 압박한다. 이때, 길이 증가가 단순히 무작위 토큰을 추가하는 것이 아니라, 음성‑텍스트 정렬을 유지하면서도 의미 없는 반복을 만들도록 설계되어, 디코더의 beam search와 같은 탐색 과정에서 연산량이 급증한다.
계층적 최적화는 두 목표를 순차적으로 달성하도록 설계돼, 첫 단계에서 충분히 높은 Word Error Rate(WER)를 확보한 뒤, 두 번째 단계에서 효율성 저하를 극대화한다. 이는 다목적 공격에서 흔히 발생하는 목표 간 상충 문제를 완화한다는 장점이 있다. 또한, 논문은 REDO가 “repetitive encouragement”이라는 개념을 도입해, 모델이 이미 오류가 난 상태에서 추가적인 “복제”를 스스로 학습하도록 만든다. 이 과정에서 gradient‑based 공격(예: PGD, FGSM)과의 결합이 가능하며, 공격 성공률을 크게 높인다.
실험에서는 Whisper‑large, Whisper‑medium 등 다양한 규모의 사전학습된 ASR 모델에 대해 평가했으며, 기존의 단일 목표(정확도 저하) 공격에 비해 전사 길이가 평균 2.3배~4.7배 증가하고, WER은 15%~30% 포인트 상승했다. 특히, 연산 비용(플롭스)과 추론 시간도 유의미하게 늘어나, 실시간 서비스 환경에서의 취약점을 명확히 드러낸다. 이러한 결과는 ASR 시스템이 단순히 정확도만이 아니라, 효율성 측면에서도 방어 메커니즘을 재고해야 함을 시사한다.
한계점으로는 REDO가 텍스트 길이 증가에 초점을 맞추다 보니, 음성 신호 자체의 변형(예: 음성 품질 저하)에는 직접적인 영향을 주지 못한다는 점이다. 또한, 공격이 성공하려면 일정 수준 이상의 연산 자원이 필요하므로, 제한된 환경에서는 적용이 어려울 수 있다. 향후 연구에서는 음성‑레벨 변형과 텍스트‑레벨 변형을 동시에 최적화하는 통합 프레임워크를 제안하거나, 방어 측면에서 “length‑regularization”과 같은 새로운 정규화 기법을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기