다목적 조합 최적화의 적대적 인스턴스 생성과 강인 학습
초록
본 논문은 다목적 조합 최적화 문제(MOCOP)를 풀기 위한 선호 기반 강화학습(DRL) 솔버의 강인성을 체계적으로 평가하고 향상시키는 프레임워크를 제안한다. 선호 조건에 따라 적대적 공격을 설계해 Solver가 취약한 “hard instance”를 자동 생성하고, 파레토 전선 품질 저하 정도로 공격 효과를 정량화한다. 이어서, 공격으로 얻은 어려운 인스턴스와 다양한 선호를 동시에 학습에 포함하는 “hardness‑aware preference selection” 방식을 도입한 적대적 훈련(Adversarial Training) 기법을 제시한다. MOTSP, MOCVRP, MOKP 세 가지 벤치마크에 대해 기존 DRL 솔버와 비교 실험을 수행했으며, 공격이 실제로 Solver의 약점을 드러내는 것을 확인하고, 방어 기법이 OOD(Out‑of‑Distribution) 상황에서도 파레토 전선 품질을 크게 향상시킴을 입증한다.
상세 분석
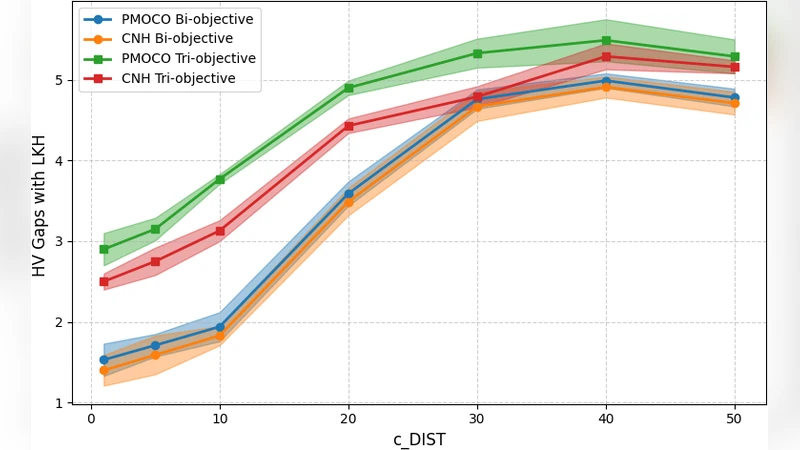
본 연구는 다목적 조합 최적화 문제에 대한 강화학습 기반 솔버가 실제 적용 단계에서 마주할 수 있는 “강인성 부족” 문제를 두 축(공격·방어)으로 접근한다. 먼저, 기존 DRL 솔버는 특정 선호(Preference) 벡터에 대해 훈련·테스트가 이루어지는 경우가 대부분이며, 이는 선호 공간 전체를 고르게 커버하지 못한다는 한계가 있다. 논문은 이를 “선호 편향(preference bias)”이라고 정의하고, 이러한 편향이 파레토 전선의 균형성·다양성에 미치는 영향을 정량화한다.
1. 적대적 공격 설계
- 목표 함수: 주어진 선호 벡터 𝜔에 대해, Solver가 생성한 파레토 해 집합 S(𝜔)와 최적 파레토 전선 PF* 사이의 거리(예: Hypervolume Gap, IGD)를 최대화하도록 인스턴스 파라미터 θ를 조정한다.
- 공격 변수: 그래프 기반 문제(MOTSP, MOCVRP)의 경우 노드 좌표, 거리 행렬, 수요·용량 등을, 이진 선택 문제(MOKP)의 경우 아이템 무게·가치·상관관계 등을 연속/이산 변수로 설정한다.
- 최적화 방법: 차별적 진화 전략(Differential Evolution) 혹은 정책 그라디언트 기반 메타‑옵티마이저를 사용해 θ를 업데이트한다. 이때 Solver는 고정된 파라미터를 가진 “black‑box” 모델로 취급되어, 공격자는 오직 출력 파레토 품질만을 관찰한다.
- 선호 조건 다양화: 공격 과정에서 𝜔를 무작위 샘플링하거나, Solver가 상대적으로 약한 선호 구간을 탐지해 집중 공격한다. 이렇게 하면 “hard instance”가 특정 선호에 국한되지 않고, 전체 선호 공간에 걸쳐 존재함을 보장한다.
2. 방어 전략 – Hardness‑Aware Preference Selection (HAPS)
- 데이터 증강: 공격 단계에서 생성된 Hard Instance 집합 H와 기존 훈련 데이터 D를 합쳐 D′ = D ∪ H 로 만든다.
- 선호 샘플링: 단순히 균등하게 선호를 샘플링하는 것이 아니라, 현재 Solver가 낮은 성능을 보이는 선호 영역에 가중치를 부여한다. 구체적으로, 각 선호 𝜔에 대해 최근 에피소드의 파레토 품질 지표 Q(𝜔)를 추정하고, 가중치 w(𝜔) ∝ 1 / (Q(𝜔)+ε) 로 정의한다.
- 멀티‑태스크 학습: 강화학습 에이전트는 “Preference‑Conditioned Policy π(a|s,𝜔)”를 학습한다. HAPS는 기존 정책 그라디언트에 추가적인 “hardness regularizer” L_hard = E_{(s,𝜔)∈H}
댓글 및 학술 토론
Loading comments...
의견 남기기