LLM 기반 구조적 분해와 시맨틱 웹 통합을 통한 규칙 기반 추론
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 대규모 언어 모델(LLM)을 온톨로지 인스턴스 생성 엔진으로 활용하고, SWRL 기반 심볼릭 추론기로 규칙 적용을 보장하는 통합 프레임워크를 제안한다. 텍스트를 엔터티 식별·단언 추출·심볼릭 검증의 세 단계로 구조화하여, 임상 시험 적격성, 법률 증언 판단, 과학적 방법론 적용 등 세 분야에서 실험을 수행하였다. 구조적 분해는 기존 few‑shot 프롬프트 대비 전반적인 정확도 향상을 보였으며, 심볼릭 검증이 없는 경우보다 의미 있는 성능 차이가 확인되었다.
상세 분석
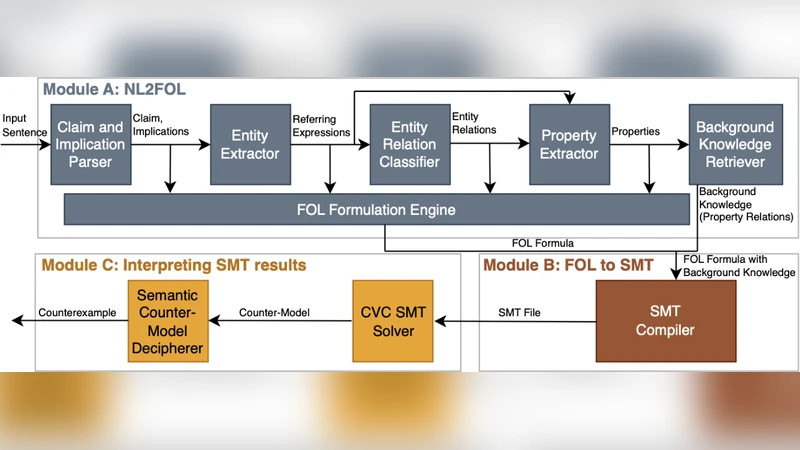
이 연구는 LLM의 자연어 이해 능력과 전통적인 시맨틱 웹 기술의 논리적 확정성을 결합하려는 시도로, 기존 접근법이 갖는 두 가지 근본적인 한계를 동시에 해결한다. 첫째, LLM은 비구조화된 텍스트를 자유롭게 해석할 수 있지만, 동일 입력에 대해 일관된 출력 보장을 제공하지 못한다. 둘째, 전통적인 OWL·SWRL 기반 시스템은 명시적 구조를 전제로 하여 입력 전처리 비용이 크게 증가한다. 논문은 이러한 문제를 ‘구조적 분해(Structured Decomposition)’라는 세부 작업 흐름으로 정의한다.
- 엔터티 식별(Entity Identification) 단계에서는 사전 정의된 TBox(클래스·속성·관계)와 매핑된 프롬프트를 사용해 LLM이 텍스트 내 핵심 개념을 추출한다. 여기서 모델은 ‘클래스명·인스턴스·속성값’ 형태의 시멘틱 라벨을 생성한다.
- 단언 추출(Assertion Extraction) 단계는 식별된 엔터티를 기반으로 ABox(개체·관계·속성) 트리플을 구성한다. 이 과정에서 LLM은 자연어 문장을 OWL 2 DL 호환 구문으로 변환하고, 다중 후보를 생성해 신뢰도 점수를 부여한다.
- 심볼릭 검증(Symbolic Verification) 단계에서는 SWRL 규칙 엔진이 생성된 ABox에 대해 결정론적 추론을 수행한다. 규칙은 전문가가 설계한 TBox에 명시된 논리적 제약을 그대로 반영하므로, 결과는 재현 가능하고 감사 가능하다.
실험 설계는 세 도메인(법률 hearsay 판단, 과학적 방법 적용, 임상 시험 적격성)에서 11개의 LLM(다양한 파라미터 규모 및 사전학습 데이터)으로 교차 검증하였다. 성능 평가는 정확도·정밀도·재현율을 포함했으며, 구조적 분해를 적용한 경우 평균 7.3%p의 정확도 상승을 기록했다. 특히, 심볼릭 검증을 제외한 ‘구조적 프롬프트만’ 실험에서는 평균 3.1%p 정도의 개선에 그쳐, 규칙 기반 검증이 성능 향상의 핵심 요인임을 확인하였다.
또한, ABox를 표준 시맨틱 웹 툴(Protege, Apache Jena)과 연동함으로써, 결과를 시각화·쿼리·추가 추론에 활용할 수 있는 확장성을 제공한다. 이는 단순 텍스트 기반 LLM 출력이 제공하지 못하는 투명성 및 인터페이스 호환성을 의미한다.
전체적으로 이 논문은 LLM과 시맨틱 웹의 시너지 효과를 구체적인 작업 흐름과 실증적 평가를 통해 입증했으며, 규칙 기반 의사결정이 요구되는 분야에서 실용적인 구현 로드맵을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기