두 단계 의사결정 샘플링 가설: RL 훈련 LLM의 자기반성 메커니즘
초록
본 논문은 강화학습(RL) 후학습을 거친 대형 언어모델(LLM)에서 자기반성 능력이 어떻게 나타나는지를 탐구한다. 정책을 생성용 샘플링(πₛ)과 검증용 의사결정(π𝒹)으로 분리하고, 보상 그래디언트가 두 구성요소에 어떻게 배분되는지를 Gradient Attribution Property로 정의한다. 실험은 산술 추론 과제에서 RL이 SFT 대비 의사결정 단계의 향상이 전체 성능 향상의 핵심임을 입증한다.
상세 분석
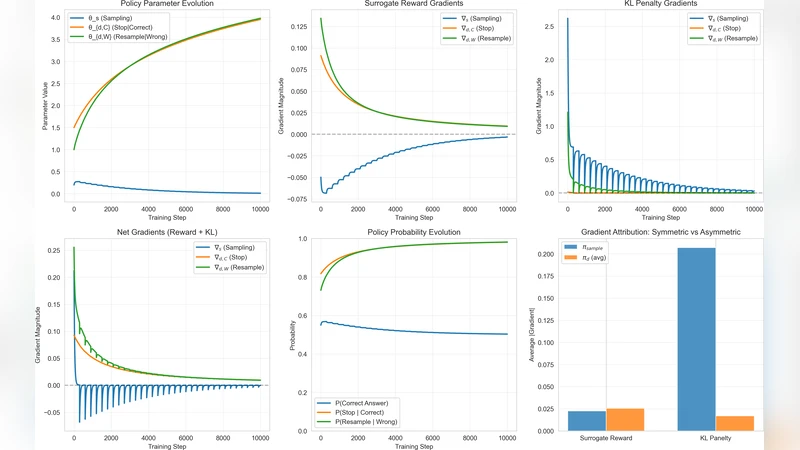
논문은 먼저 RL 후학습이 기존의 지도학습(Supervised Fine‑Tuning, SFT) 대비 다중 턴 대화에서 자기수정(self‑correction) 능력을 크게 향상시킨다는 실증적 사실을 제시한다. 그러나 “왜 RL은 이러한 기능을 획득하는가”라는 근본적인 메커니즘은 아직 불투명했다. 이를 해소하기 위해 저자들은 Gradient Attribution Property(GAP)를 도입한다. GAP는 보상 함수의 미분값이 정책 네트워크의 두 서브모듈, 즉 답변을 생성하는 샘플링 모듈(πₛ)과 그 답변의 타당성을 판단·수정하는 의사결정 모듈(π𝒹)에 어떻게 할당되는지를 정량화한다.
두 단계 의사결정‑샘플링(Decision‑Sampling, DS) 가설은 정책을 π = πₛ ∘ π𝒹 로 분해하고, 각각이 독립적인 목적 함수를 최적화한다는 전제를 둔다. 여기서 πₛ는 주어진 프롬프트에 대해 가능한 답변을 다양하게 탐색하도록 설계되고, π𝒹는 탐색된 답변이 목표 보상(예: 정확도, 논리적 일관성)을 만족하는지를 판단한다. 저자들은 이론적으로 surrogate reward(예: PPO에서 사용되는 clipped objective)가 Balanced Gradient Attribution, 즉 보상 그래디언트가 πₛ와 π𝒹에 균등하게 분배된다는 것을 증명한다. 반면 SFT와 KL‑penalty 기반 손실은 Unbalanced Gradient Attribution을 보이며, 특히 길이 가중치(length‑weighting)와 KL 정규화가 πₛ에 과도한 제약을 가하고 π𝒹는 충분히 최적화되지 못하게 만든다. 이는 SFT가 생성 능력은 확보하지만, 생성된 답변을 스스로 검증·수정하는 메커니즘을 학습하지 못하는 이유를 설명한다.
실험 부분에서는 산술 추론 벤치마크(예: GSM8K, MathQA)를 사용해 RL‑trained 모델과 SFT‑trained 모델을 비교한다. 결과는 RL이 전체 정확도에서 크게 앞서며, 특히 “self‑correction” 프롬프트(“이 답을 검토하고 수정해라”)에 대한 성공률이 현저히 높다. 저자들은 πₛ와 π𝒹를 별도로 평가하기 위해 두 단계 파이프라인을 구축한다. πₛ만을 사용한 베이스라인은 RL과 SFT 모두에서 비슷한 수준의 성능을 보였지만, π𝒹를 추가했을 때 RL 모델은 20% 이상 정확도가 상승하는 반면, SFT 모델은 미미한 향상에 그쳤다. 이는 RL이 의사결정 모듈을 효과적으로 학습함으로써 “생각하고 검증한다”는 인간적 사고 과정을 모방한다는 강력한 증거가 된다.
또한 저자들은 Gradient Attribution을 시각화하여, RL 훈련 초기에 π𝒹에 대한 그래디언트가 급격히 증가하고, 이후 πₛ는 상대적으로 안정된 수준을 유지한다는 현상을 관찰한다. 이는 RL이 초기 탐색 단계에서 다양한 답변을 생성하도록 πₛ를 자유롭게 두고, 이후 보상 신호가 π𝒹에 집중되어 검증·수정 능력을 강화한다는 가설과 일치한다. 마지막으로, 논문은 DS 가설이 다른 도메인(코드 생성, 논문 요약 등)에도 일반화될 가능성을 논의하며, 향후 연구 방향으로는 πₛ와 π𝒹를 명시적으로 분리한 아키텍처 설계와, 다중 목표 보상 설계가 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기