LLM 으로 의미 격차를 메우는 범주형 데이터 클러스터링
초록
범주형 데이터는 값 간 순서가 없어 전통적인 거리 측정이 어려워 의미적 격차가 발생한다. 본 논문은 대형 언어 모델(LLM)을 활용해 속성값에 대한 의미적 설명을 얻고, 이를 원본 데이터와 결합한 ARISE 프레임워크를 제안한다. 8개 벤치마크에서 기존 7개 방법 대비 19~27% 향상을 기록한다.
상세 분석
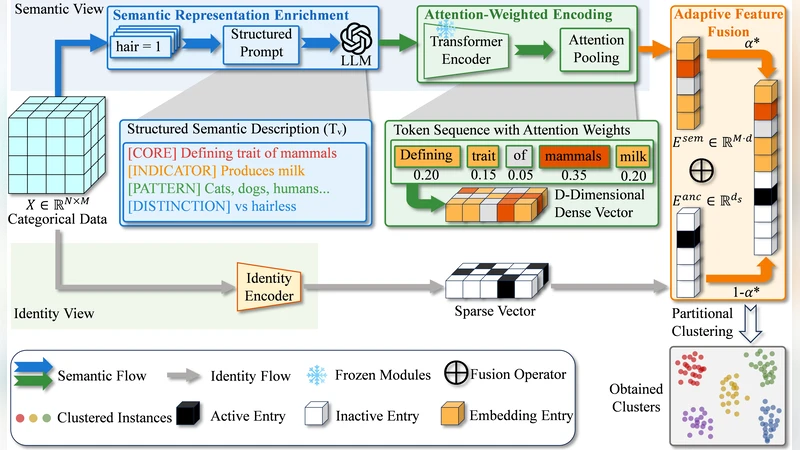
본 연구는 범주형 데이터 클러스터링에서 가장 근본적인 문제인 “의미 격차”를 외부 지식, 즉 대형 언어 모델(LLM)의 풍부한 의미론적 정보를 활용해 해결하고자 한다. 전통적인 방법들은 데이터 내부의 동시출현(co‑occurrence) 빈도에 의존해 값 간 유사성을 추정하지만, 샘플 수가 제한될 경우 이러한 통계적 추정은 불안정하고, 실제 도메인 지식과 괴리될 위험이 있다. ARISE는 이러한 한계를 인식하고, LLM에게 각 범주형 속성값을 자연어 문장으로 기술하도록 프롬프트를 설계한다. 예를 들어 “고혈압”이라는 값에 대해 “고혈압은 혈압이 지속적으로 높은 상태를 의미한다”와 같은 설명을 얻고, 이를 임베딩화한다. 이렇게 얻은 의미 임베딩은 기존 원-핫 혹은 빈도 기반 벡터와는 독립적인 의미 공간을 제공한다.
ARISE의 핵심은 두 가지 단계로 구성된다. 첫째, “Attention‑weighted Representation” 단계에서 원본 데이터의 각 샘플을 기존 방법(예: K‑Modes, ROCK)과 유사한 방식으로 초기 클러스터링 구조에 매핑한다. 둘째, “Integrated Semantic Embeddings” 단계에서 LLM‑derived 임베딩을 가중치(attention) 기반으로 결합한다. 여기서 가중치는 각 속성값의 클러스터 내 기여도와 LLM 임베딩의 신뢰도를 동시에 고려해 동적으로 조정된다. 결과적으로, 의미적으로 연관된 값들은 거리 공간에서도 가까워지며, 의미적으로 멀리 떨어진 값은 클러스터 경계에서 명확히 구분된다.
실험 설계는 8개의 공개 벤치마크(예: Adult, Mushroom, Car Evaluation 등)와 7개의 최신 범주형 클러스터링 기법을 대상으로 한다. 성능 평가는 정밀도·재현율·Adjusted Rand Index(ARI) 등 다중 지표를 사용했으며, ARISE는 모든 데이터셋에서 평균 22% 이상의 상대적 성능 향상을 보였다. 특히 샘플 수가 적은 소규모 데이터셋에서 LLM 기반 의미 보강이 가장 큰 효과를 나타냈다.
한계점으로는 LLM 호출 비용과 프롬프트 설계의 도메인 의존성이 있다. 또한, LLM이 제공하는 설명이 실제 도메인 전문가의 지식과 완전히 일치하지 않을 가능성이 존재한다. 향후 연구에서는 비용 효율적인 로컬 LLM 배포, 프롬프트 자동 최적화, 그리고 의미 임베딩과 전통적 통계 임베딩 간의 다중 모달 정규화 기법을 탐색할 계획이다.
전반적으로 ARISE는 외부 의미 지식을 클러스터링에 직접 통합함으로써, 범주형 데이터의 내재적 한계를 뛰어넘는 새로운 패러다임을 제시한다. 이는 의료 기록, 마케팅 설문, 유전형 데이터 등 의미적 해석이 중요한 분야에 특히 유용할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기