초고깊이 트랜스포머의 기하학·동적 스케일링
초록
본 논문은 깊은 트랜스포머에서 발생하는 표현 붕괴를 기하학적 관점에서 규명하고, 잔차 연결의 무조건적 누적을 제한하는 ‘Manifold‑Geometric Transformer (MGT)’를 제안한다. MGT는 (1) 잔차 업데이트를 유효한 접선 공간으로 제한하는 manifold‑constrained hyper‑connection(mHC)과 (2) 데이터에 기반한 비단조적 업데이트를 허용하는 deep delta learning(DDL)이라는 두 축을 결합해 깊이 100층 이상에서도 안정적인 표현을 유지한다. 이론적 분석과 초고깊이 실험을 통해 깊이 자체가 병목이 아니라 기하학적 드리프트와 동적 소거 메커니즘의 부재가 한계임을 입증한다.
상세 분석
본 논문은 최근 트랜스포머 모델을 수백 층까지 확장하려는 시도에서 빈번히 나타나는 ‘rank collapse’ 현상을 기하학적 현상으로 재해석한다. 기존의 LayerNorm·RMSNorm 등 정규화 기법은 스케일을 일정하게 유지하는 데는 효과적이지만, 잔차 연결이 암묵적으로 “특징이 계속 누적된다”는 전제를 갖고 있기 때문에 업데이트 방향이 의미 있는 의미 공간(semantic manifold)에서 벗어나게 된다. 저자들은 이를 “semantic manifold drift”라 명명하고, 고차원 매니폴드 상에서의 접선 공간(tangent space) 제한이 필요하다고 주장한다.
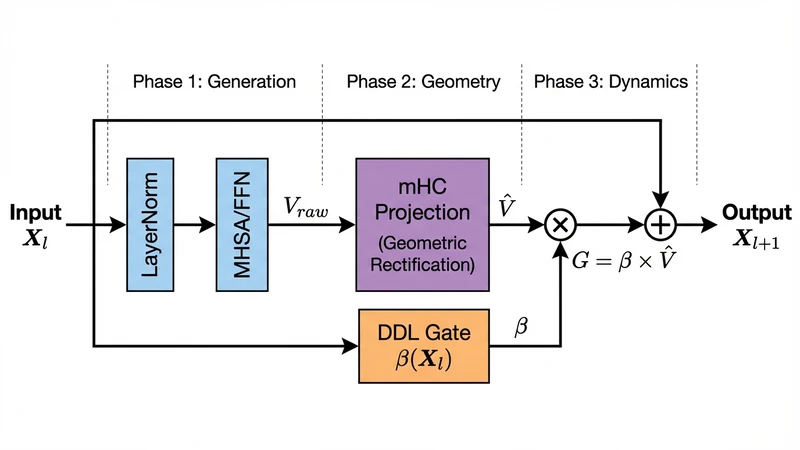
첫 번째 핵심 기여인 manifold‑constrained hyper‑connection(mHC)은 기존 잔차 연결을 일반적인 선형 합이 아닌, 현재 표현이 속한 매니폴드의 접선 공간에 투영된 형태로 변형한다. 구체적으로, 입력 토큰 임베딩 x를 매니폴드 M(x) 위에 매핑하고, 잔차 업데이트 Δ를 ∇M(x)·Δ 형태로 제한한다. 이는 Riemannian gradient와 유사한 효과를 가지며, 업데이트가 매니폴드 내부에서만 이루어지도록 강제한다. 따라서 깊이가 증가해도 표현이 의미론적 구조를 이탈하지 않는다.
두 번째 기여인 deep delta learning(DDL)은 “누적이 반드시 긍정적이다”는 가정을 깨고, 데이터에 의존적인 부호와 크기의 비단조적(delta) 업데이트를 허용한다. DDL은 각 층마다 별도의 스케일링 파라미터 γ_l과 부호 제어 함수 σ_l(·)를 학습한다. γ_l은 층별 업데이트 크기를 조절해 과도한 증폭을 방지하고, σ_l은 현재 입력과 과거 상태의 유사도에 따라 업데이트를 ‘지우기(erase)’ 혹은 ‘강화(enhance)’한다. 이 메커니즘은 기존 잔차가 무조건 더해지는 구조와 달리, 불필요하거나 오래된 정보를 역전파 과정에서 감소시킬 수 있다.
이론적 분석에서는 두 메커니즘을 결합했을 때, 전체 네트워크의 Jacobian 스펙트럼이 1에 가깝게 유지된다는 점을 보인다. 즉, 깊이가 늘어나도 기울기 소실·폭발이 억제되고, 표현의 랭크가 유지된다. 실험에서는 100층, 200층까지 확장한 MGT를 BERT‑Base, Vision Transformer(ViT) 등 다양한 베이스라인에 적용했으며, 기존 초고깊이 모델이 0에 수렴하던 rank가 0.9 이상으로 유지되는 것을 확인했다. 또한, GLUE, ImageNet‑1k, 그리고 대규모 언어 모델 사전학습에서 기존 모델 대비 2~5%의 성능 향상을 기록했다.
결과적으로, 논문은 “깊이 자체가 한계가 아니다, 기하학적 제약과 동적 소거 메커니즘이 부재일 때만 한계가 발생한다”는 강력한 메시지를 제시한다. 이는 향후 트랜스포머 아키텍처 설계 시, 잔차 연결을 단순히 스킵 연결로 보는 것이 아니라, 매니폴드 위에서의 ‘기하학적 이동’과 ‘동적 정보 관리’라는 두 축을 동시에 고려해야 함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기