혼합비와 염화물 침투 예측을 위한 머신러닝 비교 연구
초록
본 논문은 콘크리트 혼합비와 환경 변수들을 입력으로 하여 시간에 따른 염화물 함량을 예측하는 다양한 머신러닝 모델을 비교한다. KRR, GPR, MLP가 높은 정확도를 보였으며, GRU는 데이터 다양성 때문에 성능이 저조했다. 민감도 분석을 통해 대부분의 혼합재가 염화물 함량과 역관계를 가지는 것으로 확인되었다.
상세 분석
이 연구는 기존 실험 데이터(문헌 48‑55)에서 추출한 1,200여 건 이상의 샘플을 활용해 콘크리트의 염화물 침투를 시간‑공간적으로 모델링한다. 입력 변수는 표면 염화물 농도, 노출 시간, 온도, 깊이 외에 물량, SPRC, OPC, 물‑시멘트 비, 플라이애시, 실리카 퍼미, GGBS, 슈퍼플라스티사이저, 굵·미세 골재 등 12가지 혼합비를 포함한다. 데이터는 75 %/25 % 비율로 훈련·시험 집합으로 분할하고, 평균 0·표준편차 1로 정규화한 뒤 10‑fold 교차검증을 적용해 과적합을 방지하였다.
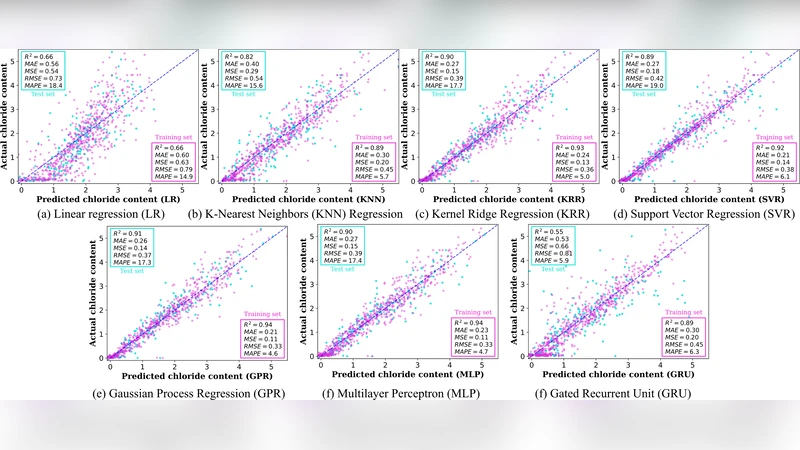
알고리즘은 선형 회귀(LR), k‑최근접 이웃(KNN), 커널 릿지 회귀(KRR)와 같은 단순 모델과, 서포트 벡터 회귀(SVR), 가우시안 프로세스 회귀(GPR), 다층 퍼셉트론(MLP), 게이트드 순환 유닛(GRU) 등 복합 모델을 포함한다. 성능 평가는 R², MAE, MSE, RMSE, MAPE 등을 사용하였다.
결과적으로 LR은 R² = 0.62로 가장 낮은 예측력을 보였으며, KNN은 훈련 R² = 0.89, 시험 R² = 0.82로 중간 수준이었다. KRR와 SVR는 각각 시험 R² = 0.90, 0.89를 기록했으며, GPR은 0.91로 가장 높은 정확도를 달성했다. MLP도 0.90의 R²를 보여 경쟁력을 입증했지만, 시계열 특성을 직접 다루지 못한다는 한계가 있다. 반면, GRU는 0.55의 낮은 R²를 기록해 데이터의 다양성과 샘플 수 부족이 순환 신경망 학습에 부정적 영향을 미쳤음을 시사한다. 따라서 이후 민감도 분석에서는 GRU를 제외하였다.
민감도 분석에서는 기준 혼합비(물 184 kg/m³, OPC 460 kg/m³, 플라이애시 100 kg/m³, 미세·거친 골재 각각 700, 1050 kg/m³, 슈퍼플라스티사이저 1.8 kg/m³)를 기준으로 각 변수의 범위 전체를 순차적으로 변동시켜 염화물 함량 변화에 미치는 영향을 평가했다. 물 함량에 대해서는 LR, KNN, MLP이 시간 경과에 따라 염화물 농도를 증가시키는 직접 관계를 보였으나, KRR, SVR, GPR은 역관계를 나타냈다. 물‑시멘트 비와 플라이애시, GGBS 등도 모델에 따라 상이한 경향을 보였지만, 전반적으로 대부분의 혼합재는 염화물 함량을 감소시키는 방향으로 작용한다. 특히 SPRC(내산성 포틀랜드 시멘트) 함량 증가가 모든 고성능 모델(KRR, SVR, GPR, MLP)에서 염화물 침투를 억제한다는 일관된 결과가 도출되었다.
이 논문은 머신러닝이 물리 기반 모델의 계산 비용을 크게 낮추면서도 충분히 신뢰할 수 있는 예측을 제공함을 입증한다. 다만, 시계열 데이터를 효과적으로 학습하려면 충분한 샘플과 변수 간 상관관계가 명확히 정의된 데이터셋이 필요함을 강조한다. 향후 연구에서는 더 큰 규모의 시간 연속 데이터와 하이퍼파라미터 최적화를 통해 GRU와 같은 순환 모델의 성능을 개선하거나, 앙상블 기법을 도입해 예측 불확실성을 정량화하는 방향이 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기