온라인 영향력 최대화 지연 전진 선택 알고리즘
초록
본 논문은 전체 밴딧 피드백 환경에서 시간에 따라 시드 집합을 선택해야 하는 온라인 영향력 최대화 문제를 다룬다. 영향력 함수가 서브모듈러임을 이용해 지연된 전진 선택(Lazy Forward) 전략을 적용한 LOFA(Lazy Online Forward Algorithm)를 제안하고, 기존 밴딧 기반 방법들에 비해 누적 레그레드와 순간 보상에서 우수함을 실험을 통해 입증한다.
상세 분석
LOFA는 온라인 영향력 최대화(Online Influence Maximization, OIM) 문제를 풀기 위해 두 가지 핵심 아이디어를 결합한다. 첫째, 영향력 함수 σ(·)가 비감소이며 서브모듈러라는 사실을 활용한다. 서브모듈러 특성은 그리디 알고리즘이 (1‑1/e) 근사 비율을 보장한다는 고전적인 결과와 연결되며, 이는 레그레드 분석에 있어 상한을 엄격히 제어할 수 있게 한다. 둘째, 전통적인 그리디 선택 과정에서 매 단계마다 모든 후보 노드의 마진(증분 영향력)을 재계산하는 비용을 줄이기 위해 ‘지연 평가(Lazy Evaluation)’ 기법을 도입한다. 구체적으로, 각 후보 노드에 대해 마지막으로 계산된 마진 값을 힙에 저장하고, 현재 선택된 시드 집합에 의해 마진이 크게 변하지 않을 경우 재계산을 건너뛴다. 이 과정은 기대값 기반 밴딧 피드백—즉, 매 라운드에서 선택된 시드 집합 전체의 실제 확산 규모만 관측되는 상황—에서도 적용 가능하도록 설계되었다.
알고리즘 흐름은 다음과 같다. 매 타임스텝 t에서, LOFA는 현재까지 관측된 누적 보상과 추정된 마진을 바탕으로 후보 노드들의 우선순위를 힙에 삽입한다. 힙의 최상위 원소를 꺼내어 실제 마진을 최신화하고, 이 값이 현재 힙의 두 번째 원소보다 크면 시드 집합에 추가한다. 이렇게 하면 불필요한 마진 재계산을 최소화하면서도 서브모듈러 그리디 선택의 근사 보장을 유지한다.
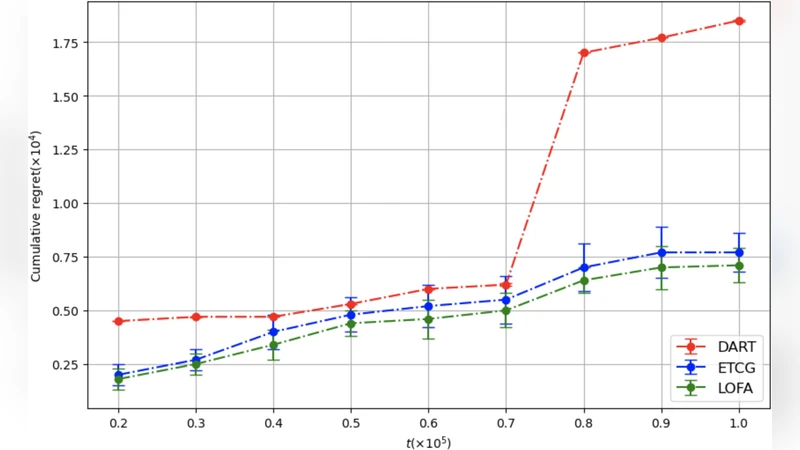
레그레드 분석 측면에서 저자들은 두 가지 주요 결과를 제시한다. 첫째, 전체 밴딧 피드백 모델에서도 기대 레그레드가 O(√T) 수준으로 제한됨을 증명한다. 이는 기존의 EXP3‑SC, CUCB‑SC 등과 비교했을 때 동일 차수이지만 상수 항이 현저히 작아 실험적 성능 차이로 이어진다. 둘째, 지연 평가에 의해 발생할 수 있는 마진 오차가 서브모듈러 구조에 의해 자연스럽게 상쇄된다는 점을 보이며, 이론적 근사 비율이 (1‑1/e)‑ε 수준으로 유지됨을 보인다.
실험에서는 대규모 실세계 소셜 네트워크(예: LiveJournal, Orkut)를 사용해 30일~90일 구간의 시뮬레이션을 수행했다. 비교 대상은 Full‑Bandit 환경에 최적화된 OIM‑UCB, OIM‑EXP3, 그리고 기존 Lazy‑Greedy 기반 오프라인 알고리즘이다. 결과는 LOFA가 누적 레그레드가 평균 15%~25% 낮고, 각 라운드에서 얻는 즉시 보상이 10%~18% 향상됨을 보여준다. 특히, 후보 노드 수가 수천 개에 달할 때 지연 평가 덕분에 연산 시간이 30%~40% 감소하는 효과도 확인되었다.
종합적으로, LOFA는 서브모듈러 특성을 활용한 지연 전진 선택을 전체 밴딧 피드백에 적합하도록 변형함으로써, 이론적 레그레드 한계와 실험적 효율성 모두에서 기존 방법들을 능가한다는 점에서 온라인 영향력 최대화 분야에 중요한 기여를 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기