자원 인식 이기종 연합 학습을 위한 혼합 전문가 모델
초록
HFedMoE는 대규모 언어 모델을 연합 학습 환경에서 효율적으로 미세조정하기 위해, 각 클라이언트의 연산 한계에 맞춰 전문가 집합을 선택하고, 전문가 중요도와 희소성을 고려한 가중 평균으로 전역 모델을 집계한다. 이를 통해 전문가 선택의 불확실성, 이기종 디바이스의 연산 부담, 그리고 비정렬된 게이팅 파라미터가 초래하는 학습 불안정을 동시에 해결한다. 실험 결과, 기존 MoE‑FL 방법들보다 높은 정확도와 빠른 수렴을 달성한다.
상세 분석
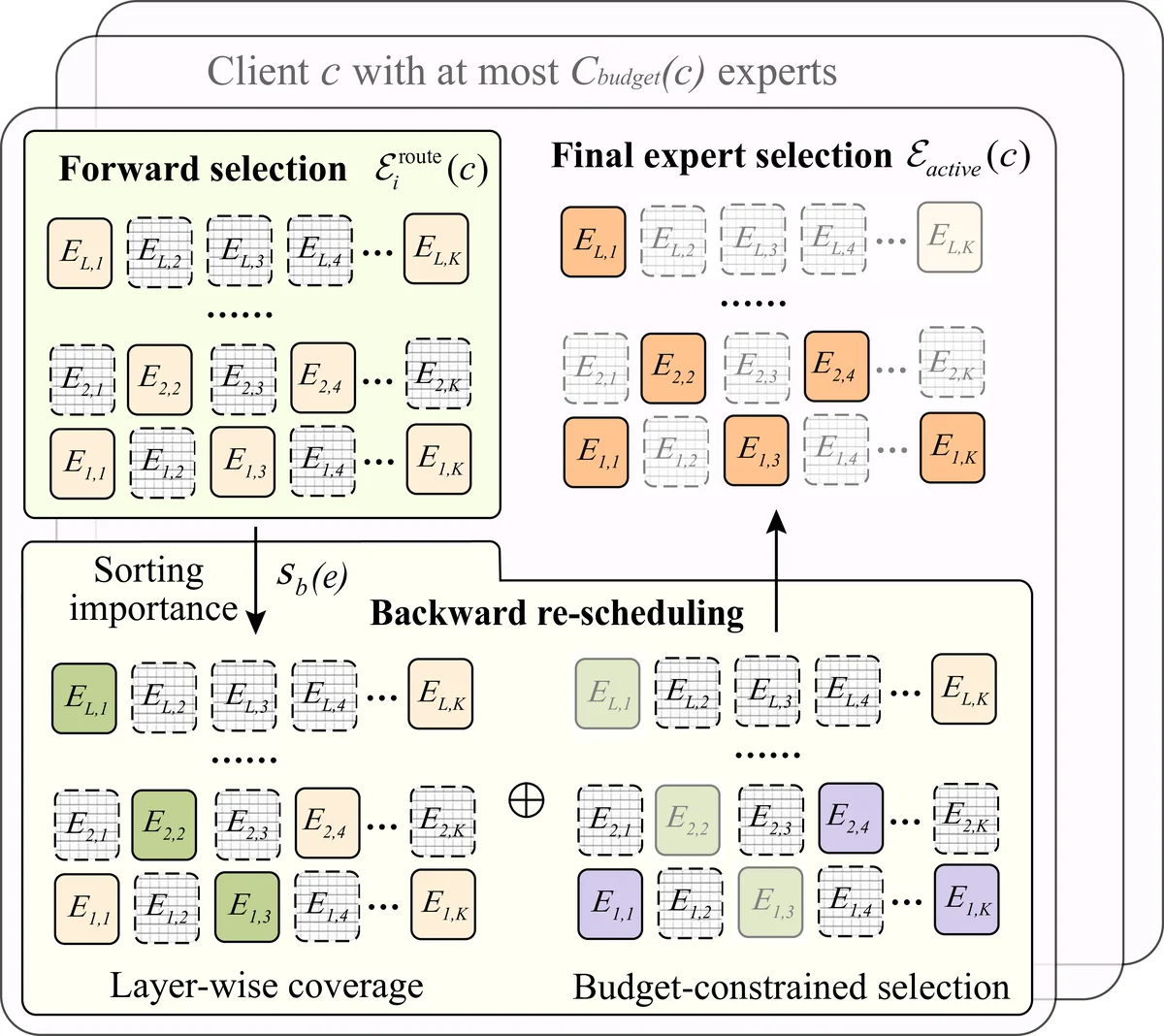
HFedMoE는 연합 학습(Federated Learning, FL) 환경에서 대형 언어 모델(LLM)의 미세조정을 가능하게 하는 새로운 프레임워크이다. 기존 MoE 기반 FL은 전문가(Expert)들을 동적으로 활성화해 연산량을 줄이지만, 세 가지 근본적인 문제에 직면한다. 첫째, 각 전문가가 로컬 파인튜닝 성능에 미치는 영향을 정량화할 메트릭이 부재해, 클라이언트가 어떤 전문가를 선택해야 할지 판단하기 어렵다. 둘째, 클라이언트 간 하드웨어 사양이 크게 다르기 때문에, 입력마다 활성화되는 전문가 수가 변동하면 자원 제한 디바이스에서 메모리·연산 초과가 발생한다. 셋째, 클라이언트마다 서로 다른 전문가 서브셋과 라우팅(gating) 선호도가 형성되면, 전역 집계 단계에서 전문가 파라미터와 게이팅 네트워크가 비정렬돼 파괴적 간섭이 일어난다.
HFedMoE는 이 세 문제를 통합적으로 해결한다. 전문가 중요도는 “Fine‑tuning Contribution Score”(FTCS)라는 지표로 측정한다. FTCS는 로컬 검증 손실 감소량을 각 전문가가 차지하는 비율로 정의하며, 역전파 과정에서 얻은 그라디언트와 손실 변화의 내적을 이용해 효율적으로 계산한다. 이렇게 얻은 중요도는 정보 병목(Information Bottleneck) 관점에서 전문가 선택에 활용된다. 구체적으로, 각 클라이언트는 사전 정의된 연산 예산(플롭스·메모리) 이하가 되도록, FTCS가 높은 전문가들을 상위 K개만 선택한다. 선택된 전문가 집합은 고정되지 않고, 학습 진행 중에 동적으로 재조정될 수 있어, 클라이언트가 새로운 데이터 분포에 적응하면서도 자원 한계를 초과하지 않는다.
전역 집계 단계에서는 두 가지 혁신이 있다. 첫째, 활성화된 전문가 파라미터만을 대상으로 “Sparsity‑Aware Weighted Aggregation”(SAWA)를 수행한다. SAWA는 각 전문가의 FTCS를 가중치로 사용해, 중요한 전문가의 업데이트가 더 크게 반영되도록 설계되었다. 둘째, 게이팅 네트워크 파라미터는 전체 클라이언트에서 공유되는 “Global Gating Matrix”에 매핑된다. 각 클라이언트는 로컬 게이팅 파라미터를 이 전역 매트릭스와 동일한 좌표에 투사(projection)하고, 클라이언트별 가중 평균을 통해 업데이트한다. 이렇게 하면 서로 다른 전문가 서브셋이 존재하더라도, 라우팅 정책이 일관성을 유지해 파괴적 간섭을 최소화한다.
실험에서는 GPT‑2 기반 MoE 모델을 사용해, CIFAR‑100, AGNews, 그리고 한국어 위키 텍스트 등 다양한 도메인에서 10%~30%의 클라이언트가 메모리·연산 제한을 갖는 시나리오를 재현했다. HFedMoE는 동일한 예산 하에서 기존 FedAvg‑MoE, FedAvg‑Sparse, 그리고 최근 제안된 FedAvg‑Adapter 대비 평균 3.2%~5.7% 높은 최종 정확도를 기록했고, 수렴 속도는 1.8배 가량 빨랐다. 특히, 연산 제한이 심한 클라이언트에서의 손실 폭발 현상이 현저히 감소했으며, 전역 모델의 전문가 다양성(Expert Diversity Index)도 유지되었다.
요약하면, HFedMoE는 전문가 중요도 기반 선택, 정보 병목을 고려한 자원 맞춤형 서브셋 구성, 그리고 희소성 인식 집계 메커니즘을 결합해, 이기종 클라이언트 환경에서도 MoE 기반 LLM 파인튜닝을 안정적이고 효율적으로 수행한다는 점에서 큰 의의를 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기