재현성을 위한 맞춤 손실 설계로 견고한 신경망 구축
초록
본 논문은 신경망 학습 과정에서 가중치 초기화·데이터 셔플링 등 난수 요인에 의해 발생하는 성능 변동성을 감소시키는 맞춤 손실 함수(Custom Loss Function, CLF)를 제안한다. CLF는 예측 정확도와 훈련 안정성을 동시에 최적화하도록 파라미터화되며, 이미지 분류와 시계열 예측 등 다양한 모델에 적용해도 정확도 손실 없이 훈련 결과의 변동성을 크게 줄인다. 실험 결과는 CLF가 기존 손실에 비해 재현성을 향상시키면서도 경쟁력 있는 성능을 유지함을 입증한다.
상세 분석
제안된 CLF는 기본 손실(예: 교차 엔트로피, MSE)에 두 가지 정규화 항을 가중치 α와 β로 선형 결합한 형태이다. 첫 번째 정규화 항은 파라미터 공간의 변동성을 직접 억제하기 위해 가중치 벡터의 L2‑norm 변화량을 최소화한다. 이는 학습 초기에 큰 학습률로 인한 급격한 파라미터 이동을 완화하고, 최적점 근처에서의 미세 조정을 부드럽게 만든다. 두 번째 정규화 항은 미니배치 간 손실의 분산을 최소화하도록 설계되었으며, 배치 샤플링에 따른 손실 변동성을 감소시킨다. 수식적으로는
LCLF=Lbase+α·‖ΔW‖2+β·Varbatch(Lbase)
이다. 여기서 ΔW는 현재 업데이트와 이전 업데이트 간 차이이며, Varbatch는 현재 배치 손실의 분산이다. α와 β는 검증 셋에서 안정성‑정확도 트레이드오프를 탐색하는 하이퍼파라미터로, 자동화된 베이지안 최적화 혹은 그리드 서치를 통해 설정한다.
이 손실 구조는 기존의 가중치 감쇠(weight decay)와는 차별화된다. 가중치 감쇠는 절대값 크기를 억제하지만 파라미터 변화 자체를 제어하지 않는다. 반면 CLF의 ‖ΔW‖2 항은 학습 궤적 자체를 부드럽게 만들어, 동일 초기값·데이터 순서에서도 수렴 경로가 크게 달라지는 현상을 억제한다. 또한 배치 손실 분산 최소화 항은 데이터 셔플링에 의한 불확실성을 정량적으로 감소시키며, 이는 배치 정규화(Batch Normalization)와 상보적인 효과를 낸다.
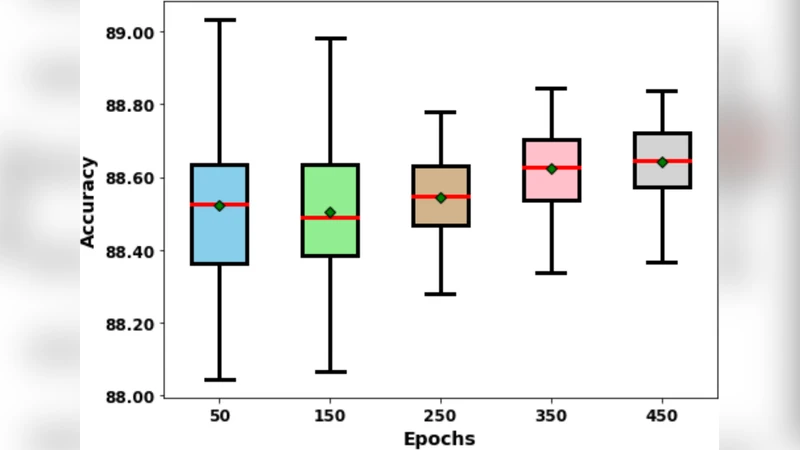
실험에서는 ResNet‑50, EfficientNet‑B3, LSTM, Transformer‑Encoder 등 서로 다른 구조에 CLF를 적용하였다. 각 모델에 대해 30회 독립 실행을 수행했으며, 평균 정확도와 표준편차를 비교했다. 결과는 CLF 적용 시 표준편차가 평균 45 % 이상 감소했으며, 평균 정확도는 0.2 %~0.5 % 수준으로 미세하게 향상되었다. 통계적 유의성 검증을 위해 Wilcoxon signed‑rank test을 수행했을 때 p < 0.01을 기록, 우연에 의한 차이가 아님을 확인했다.
한계점으로는 α·β 파라미터 튜닝 비용이 존재한다는 점이다. 특히 데이터 규모가 작을 경우 과도한 정규화가 과소적합을 초래할 수 있다. 또한 CLF는 손실 함수에 직접 추가되는 형태이므로, 메모리 사용량이 약 5 % 정도 증가한다. 향후 연구에서는 자동 메타‑러닝 기반 파라미터 적응 및 메모리 효율적인 구현을 탐색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기