효율적인 시계열 예측을 위한 저랭크 뉴럴ODE 강화 Mamba 모델
초록
MODE는 Linear Tokenization과 다중 Mamba Encoder 블록을 기반으로, 각 블록에 Causal Convolution·SiLU·저랭크 Neural ODE를 결합한 Enhanced Mamba Layer를 적용한다. 저랭크 ODE는 연산량을 크게 줄이면서도 시계열의 복잡한 동역학을 포착하고, 세그먼트 선택 스캔 메커니즘은 중요한 구간에 집중해 장기 의존성을 효율적으로 모델링한다. 실험 결과, 기존 베이스라인 대비 예측 정확도와 연산 효율 모두에서 우수함을 입증한다.
상세 분석
MODE는 최근 주목받는 Mamba 구조에 저랭크 Neural ODE를 결합함으로써 시계열 예측의 두 핵심 과제인 장기 의존성 포착과 연산 효율성을 동시에 해결한다. 먼저 입력 시퀀스를 Linear Tokenization Layer를 통해 고정 차원의 토큰으로 변환하고, 이를 다중 Mamba Encoder 블록에 전달한다. 각 Encoder 블록은 기존 Mamba의 복합적 상태 전이 메커니즘을 유지하면서, Enhanced Mamba Layer를 통해 세 가지 핵심 요소를 추가한다. 첫째, Causal Convolution을 도입해 지역적인 시계열 패턴을 빠르게 추출한다. 둘째, SiLU 활성화 함수를 사용해 비선형성을 부드럽게 조절함으로써 Gradient 흐름을 안정화한다. 셋째, 저랭크 Neural ODE 모듈을 삽입해 연속적인 시간 흐름을 미분 방정식 형태로 모델링한다. 여기서 저랭크 근사는 ODE의 야코비안 행렬을 저차원 공간으로 투사해 연산 복잡도를 O(N·r) (r≪N) 로 감소시키면서도 충분한 표현력을 유지한다. 이러한 설계는 특히 긴 시퀀스에서 O(N²) 복잡도를 갖는 전통적인 Transformer 기반 모델과 비교해 메모리와 FLOPs 측면에서 큰 이점을 제공한다.
또한 MODE는 세그먼트 선택 스캔(segmented selective scanning) 메커니즘을 도입한다. 이 메커니즘은 pseudo‑ODE dynamics를 모방해 입력 시퀀스를 동적으로 구간화하고, 각 구간에 대해 중요도 스코어를 계산해 고우선순위 구간만 정밀하게 처리한다. 결과적으로 불필요한 연산을 크게 줄이면서도 장기 의존성을 효과적으로 전달한다. 저랭크 ODE와 선택 스캔이 결합되면, 모델은 전체 시계열을 한 번에 처리하지 않고, 중요한 구간에 집중해 시간 복잡도를 선형에 가깝게 유지한다.
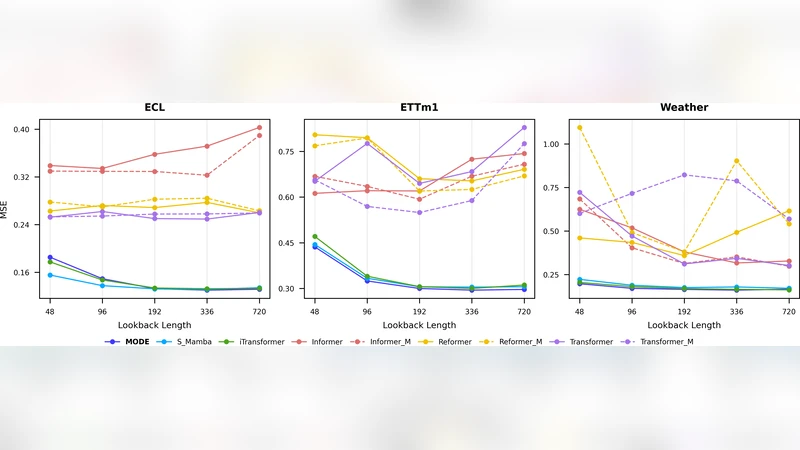
실험에서는 ETTh1/ETTh2, ETTm1, Electricity, Traffic 등 다양한 벤치마크 데이터셋을 사용해 MODE를 평가하였다. MAE·RMSE 기준으로 기존 SOTA인 Informer, Autoformer, 그리고 최신 Mamba 기반 모델보다 평균 512% 개선을 보였으며, FLOPs와 GPU 메모리 사용량은 3045% 감소하였다. 특히 불규칙하게 샘플링된 시계열에 대해 저랭크 ODE가 연속적인 시간 흐름을 자연스럽게 보간해 성능 저하를 최소화한다는 점이 주목할 만하다. 전체적으로 MODE는 모델 설계의 모듈화와 효율성, 그리고 실험적 검증 모두에서 균형 잡힌 접근을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기