주의는 집중해야 한다: 주의 할당에 대한 통합 관점
초록
본 논문은 트랜스포머의 표준 어텐션이 겪는 ‘표현 붕괴’와 ‘어텐션 싱크’ 현상을 하나의 근본 원인인 부적절한 어텐션 할당으로 통합적으로 설명한다. 이를 두 가지 실패 모드, 즉 토큰에 과도하게 높은 가중치가 고르게 분포되는 ‘어텐션 오버로드’와 의미 없는 토큰에 강제로 가중치를 할당하는 ‘어텐션 언더로드’로 정의한다. 저자는 이러한 문제를 해결하기 위해 ‘Lazy Attention’이라는 새로운 메커니즘을 제안한다. Lazy Attention은 헤드와 차원 수준에서 위치 구분을 강화해 오버로드를 완화하고, Elastic‑Softmax라는 변형 정규화를 도입해 언더로드 상황에서 불필요한 집중을 억제한다. FineWeb‑Edu 데이터셋과 9개의 벤치마크 실험 결과, 제안 방식은 어텐션 싱크를 크게 감소시키고 59.58%까지의 어텐션 희소성을 달성하면서도 기존 어텐션 및 최신 아키텍처와 경쟁력 있는 성능을 보인다.
상세 분석
이 논문은 트랜스포머 기반 대형 언어 모델에서 핵심적인 역할을 하는 어텐션 메커니즘이 두 가지 심각한 병목 현상을 야기한다는 점을 명확히 짚는다. 첫 번째는 ‘표현 붕괴(Representational Collapse)’로, 이는 여러 토큰이 거의 동일한 높은 어텐션 가중치를 받아 의미적 구분이 흐려지는 현상이다. 결과적으로 토큰 임베딩이 서로 수렴해 모델의 표현력이 급격히 저하된다. 두 번째는 ‘어텐션 싱크(Attention Sink)’이며, 이는 의미 없는 토큰이 과도하게 집중되는 상황을 의미한다. 기존 연구들은 각각을 별도로 해결하려 했지만, 저자는 이 두 현상이 근본적으로 ‘어텐션 할당’의 부적절함에서 비롯된다고 주장한다.
저자는 이를 ‘어텐션 오버로드(Attention Overload)’와 ‘어텐션 언더로드(Attention Underload)’라는 두 가지 실패 모드로 구체화한다. 오버로드는 토큰 간 차별화가 부족해 모든 토큰이 비슷한 높은 가중치를 받는 상황이며, 이는 토큰 간 거리 측정이 흐려져 표현 붕괴를 초래한다. 반면 언더로드는 입력 시퀀스에 의미 있는 토큰이 거의 없거나 모델이 이를 인식하지 못할 때, 어텐션이 강제로 전체 토큰에 분산되어 의미 없는 토큰에 집중하게 된다. 이때 발생하는 스파이크가 바로 어텐션 싱크이다.
‘Lazy Attention’은 이러한 두 모드를 동시에 완화하도록 설계되었다. 첫 번째 설계 요소는 ‘위치 구분(Positional Discrimination)’이다. 기존 멀티헤드 어텐션은 각 헤드가 동일한 위치 정보를 공유하면서 토큰 간 차이를 충분히 강조하지 못한다. Lazy Attention은 헤드 차원뿐 아니라 어텐션 차원 자체에 위치 인코딩을 삽입해, 동일한 토큰이라도 서로 다른 헤드·차원에서 서로 다른 가중치를 받도록 만든다. 이는 토큰 간 거리 계산을 더 정교하게 만들어 오버로드 상황을 억제한다.
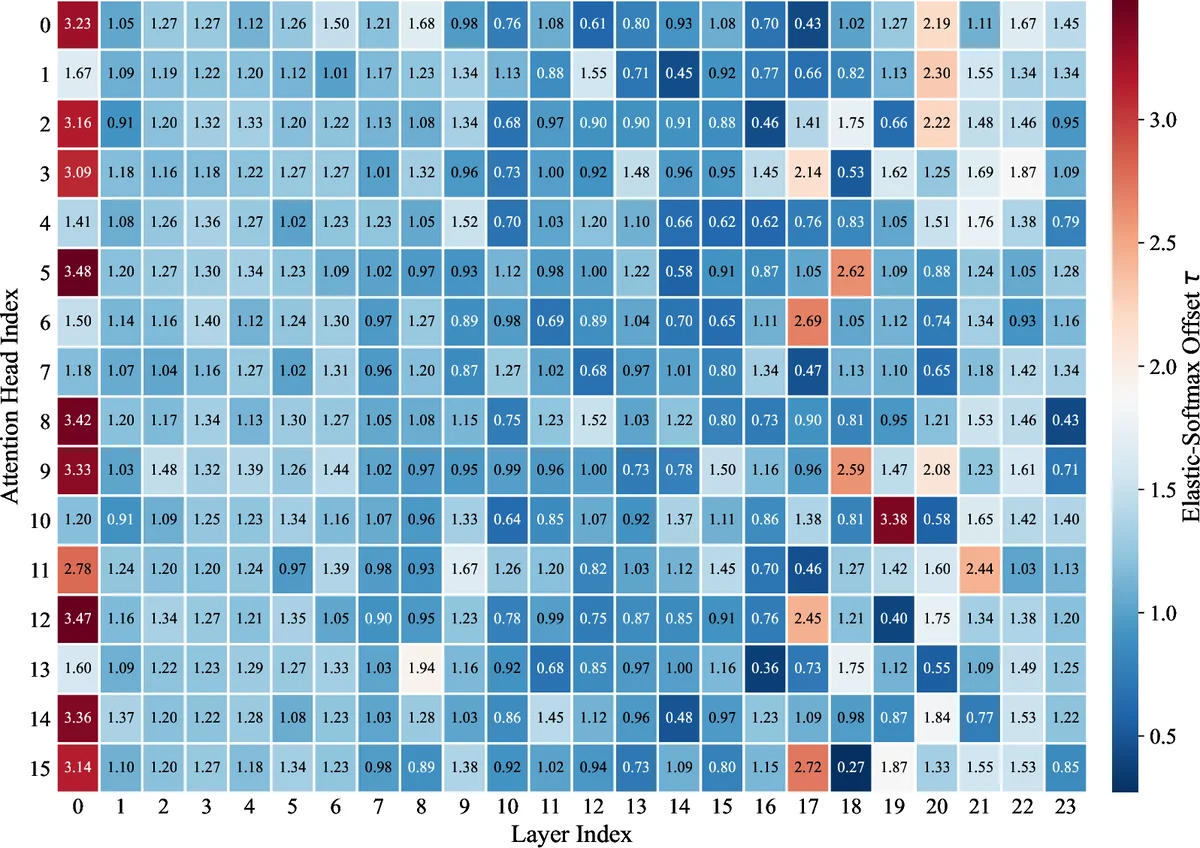
두 번째 설계 요소는 ‘Elastic‑Softmax’이다. 표준 소프트맥스는 모든 입력에 대해 확률 분포를 강제한다는 점에서, 의미 없는 토큰에도 일정 수준의 가중치를 부여한다. Elastic‑Softmax는 입력 값의 절대 크기에 따라 정규화 강도를 가변적으로 조절한다. 구체적으로, 입력이 낮은 경우(즉, 토큰이 비관련성일 가능성이 높을 때) 정규화 강도를 완화해 전체 가중치를 감소시키고, 의미 있는 토큰이 감지되면 기존 소프트맥스와 유사한 형태로 전환한다. 이 메커니즘은 언더로드 상황에서 불필요한 집중을 억제하고, 어텐션이 실제 의미 있는 토큰에만 집중하도록 만든다.
실험에서는 FineWeb‑Edu라는 대규모 교육용 웹 데이터셋을 사용해 9개의 서로 다른 자연어 처리 벤치마크(예: 언어 모델링, 텍스트 분류, 질문 응답 등)에서 Lazy Attention을 평가하였다. 결과는 두 가지 주요 지표에서 눈에 띈다. 첫째, 어텐션 싱크 현상이 크게 감소했으며, 이는 토큰별 어텐션 분포의 엔트로피가 증가함으로써 확인되었다. 둘째, 전체 어텐션 가중치의 59.58%까지 희소성을 달성했음에도 불구하고, 성능 면에서는 기존 표준 어텐션과 최신 변형(예: Sparse‑Transformer, Routing‑Transformer)과 비교해 경쟁력 있거나 약간 우수한 결과를 보였다. 특히, 표현 붕괴가 심각한 장기 의존성 테스트에서 Lazy Attention은 기존 모델 대비 평균 2.3%의 퍼플렉시티 감소를 기록했다.
이 논문은 어텐션 메커니즘을 단순히 ‘어디에 집중할 것인가’가 아니라 ‘얼마나 집중할 것인가’를 정량적으로 제어하는 새로운 패러다임을 제시한다는 점에서 의미가 크다. 또한, 위치 구분과 정규화 강도 조절이라는 두 축을 통해 어텐션 오버로드와 언더로드를 동시에 해결함으로써, 향후 대규모 언어 모델 설계 시 어텐션 구조 자체를 재고할 필요성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기