LLM으로 라벨링된 룩셈부르크어 NER 데이터셋 JudgeWEL 평가
초록
본 논문은 위키피디아와 위키데이터를 활용해 자동으로 라벨링한 룩셈부르크어 개체명 인식(NER) 데이터셋 judgeWEL을 소개한다. 라벨링 품질을 높이기 위해 여러 대형 언어모델(LLM)을 이용해 노이즈를 제거하고, 기존 데이터셋 대비 5배 규모의 균형 잡힌 코퍼스를 구축하였다.
상세 분석
본 연구는 저자원이 부족한 언어, 특히 룩셈부르크어와 같은 소수 언어에 대한 NER 데이터 구축 문제를 해결하고자 하는 시도이다. 위키피디아 내부 링크를 활용해 엔티티 후보를 추출하고, 해당 링크가 연결된 위키데이터 항목을 통해 엔티티 유형을 자동 매핑하는 방식은 기존의 규칙 기반 혹은 크라우드소싱 방식보다 비용 효율적이며, 언어적 편향을 최소화한다는 장점이 있다. 그러나 위키피디아 링크는 편집자에 따라 일관성이 떨어질 수 있고, 특히 소수 언어 위키에서는 링크 자체가 부족하거나 부정확한 경우가 많다. 이를 보완하기 위해 저자들은 GPT‑3.5, Claude, Llama‑2 등 다양한 LLM을 활용해 “라벨 품질 검증” 단계에서 노이즈를 걸러냈다. 여기서 흥미로운 점은 LLM을 “판사(Judge)” 역할로 전환함으로써, 인간 라벨러 없이도 라벨 신뢰도를 일정 수준 확보했다는 점이다. 다만, LLM 자체가 학습 데이터에 편향을 내포하고 있을 가능성이 있어, 검증 단계에서 발생할 수 있는 시스템적 오류를 완전히 배제하기는 어렵다.
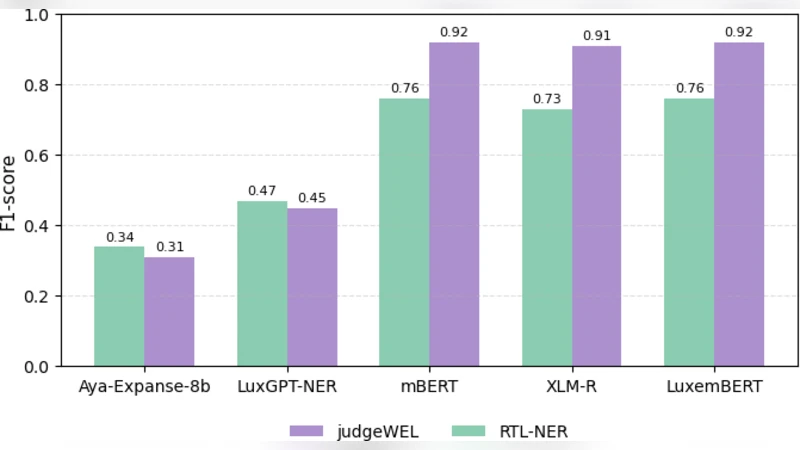
실험에서는 기존 룩셈부르크어 NER 벤치마크인 “LuxNER”와 비교해, judgeWEL이 엔티티 유형별 커버리지를 크게 확대했으며, 특히 조직명(ORG)과 위치명(LOC)에서 균형 잡힌 분포를 보였다. 또한, 다양한 LLM을 사용한 라벨 정제 과정에서 GPT‑3.5가 가장 높은 정밀도를 달성했으며, Claude와 Llama‑2는 Recall 측면에서 강점을 보였다. 이러한 결과는 LLM 선택에 따라 라벨링 파이프라인의 특성이 달라질 수 있음을 시사한다.
한계점으로는 라벨 검증에 사용된 LLM이 사전 학습된 언어 모델이므로, 실제 인간 라벨러와의 일치율을 정량적으로 제시하지 않은 점이다. 또한, 자동 라벨링 과정에서 발생한 오류가 LLM 검증 단계에서 완전히 제거되지 않을 가능성이 있다. 향후 연구에서는 인간 라벨러와의 교차 검증을 통해 LLM 기반 검증의 신뢰성을 보강하고, 다른 저자원 언어에 대한 일반화 가능성을 탐색할 필요가 있다.
전반적으로, 본 논문은 위키 기반 약한 감독(weak supervision)과 LLM 기반 라벨 검증을 결합한 새로운 데이터 구축 파이프라인을 제시함으로써, 저자원 언어 NER 연구에 실질적인 기여를 하고 있다.