유동성 게임을 위한 다중에이전트 강화학습과 합리적 스웜 모델
초록
본 논문은 유동성 게임과 합리적 스웜 이론을 결합해, 차이 보상(difference reward)을 이용한 마코프 팀 게임 프레임워크를 제시한다. 개별 트레이더는 독립적으로 학습하면서도 전체 시장 유동성이라는 집단 목표에 기여하도록 설계되었으며, 협조나 담합 없이도 개인 수익과 시장 효율성을 동시에 달성할 수 있음을 이론적으로 증명한다.
상세 분석
이 연구는 두 개의 독립적인 학문 분야—스웜 인텔리전스와 금융 시장 마이크로구조—를 연결하는 새로운 이론적 틀을 구축한다. 먼저, 저자는 “Liquidity Games”라는 개념을 도입한다. 여기서 각 트레이더의 보상은 자신이 체결한 거래의 유동성(예: 스프레드 감소, 거래량 확대)과 전체 시장 유동성 수준 사이의 함수로 정의된다. 이러한 보상 구조는 전통적인 개별 수익 중심 모델과 달리, 개별 행동이 집합적으로 시장 안정성에 미치는 영향을 정량화한다.
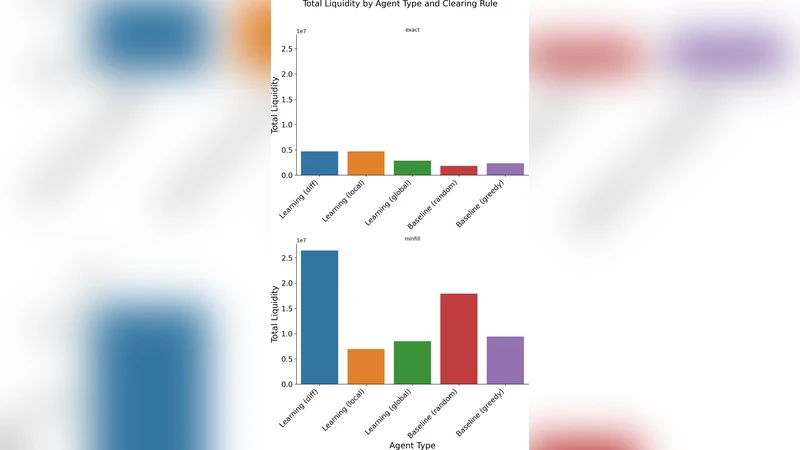
핵심 기법은 차이 보상(difference reward, D)이다. D_i = G(s) – G(s_{-i}) 형태로, 전체 시스템 성능 G(s)와 해당 에이전트 i를 제외한 상태 G(s_{-i})의 차이를 보상으로 제공한다. 이 방식은 각 에이전트가 자신의 행동이 전체에 미치는 marginal contribution을 직접 학습하도록 만든다. 차이 보상은 기존의 전역 보상(global reward)보다 신호 대 잡음비(signal‑to‑noise ratio)가 높아, 다중 에이전트 강화학습(MARL)에서 수렴 속도를 크게 향상시킨다.
마코프 팀 게임 프레임워크 내에서, 저자는 상태공간을 시장의 현재 유동성 수준, 주문 흐름, 가격 변동성 등으로 정의하고, 행동공간을 매수·매도·보류 등 기본 거래 결정으로 제한한다. 전이 확률은 실제 시장 데이터에서 추정한 확률적 주문 매칭 모델을 사용한다. 이때 차이 보상은 정책 그래디언트 기반 알고리즘(예: REINFORCE, Actor‑Critic)과 결합되어, 각 트레이더가 독립적인 정책 π_i(a|s) 를 학습한다.
이론적 분석에서는 (1) 차이 보상이 팀 전체 최적 정책을 유지하면서도 개별 정책의 편향을 최소화함을, (2) 마코프 팀 게임이 잠재적 게임(potential game) 구조를 갖추어 Nash equilibrium이 존재하고, (3) 차이 보상 기반 학습이 정책 반복을 통해 전역 최적점에 수렴함을 정리와 증명을 통해 보여준다. 특히, 잠재 함수 Φ(s) = G(s) 로 정의하면, 각 에이전트의 보상 차이는 Φ의 그라디언트와 일치하므로, 전체 시스템은 조화로운 상승곡선을 그린다.
제한점으로는 (i) 차이 보상을 계산하기 위해 전체 시스템 상태를 관찰해야 하는 “관측 비용”이 존재한다는 점, (ii) 마코프 가정이 실제 고빈도 거래의 비선형, 비정상성에 완전히 부합하지 않을 수 있다는 점, (iii) 실험에 사용된 시뮬레이션 환경이 제한된 시장 구조(이중 경매)만을 반영한다는 점을 들었다. 이러한 한계에도 불구하고, 차이 보상 기반 MARL이 금융 시장 설계에 제공할 수 있는 정책적·규제적 인사이트는 매우 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기