다중영상 딥러닝으로 조기 태반착류증 진단 혁신
초록
본 연구는 3차원 MRI와 2차원 초음파 영상을 결합한 중간 특징 수준 융합 모델을 제안한다. 3D DenseNet121‑Vision Transformer와 2D ResNet50을 각각 MRI와 초음파의 특징 추출기로 활용했으며, 1,293개의 MRI와 1,143개의 초음파 데이터를 기반으로 학습하였다. 환자별 매칭된 MRI‑US 쌍을 이용한 멀티모달 모델은 독립 테스트에서 정확도 92.5%, AUC 0.927를 기록해 단일 모달 모델(MRI 82.5%/AUC 0.825, 초음파 87.5%/AUC 0.879)을 크게 능가하였다. 결과는 두 영상 modality가 상호 보완적인 정보를 제공함을 시사한다.
상세 분석
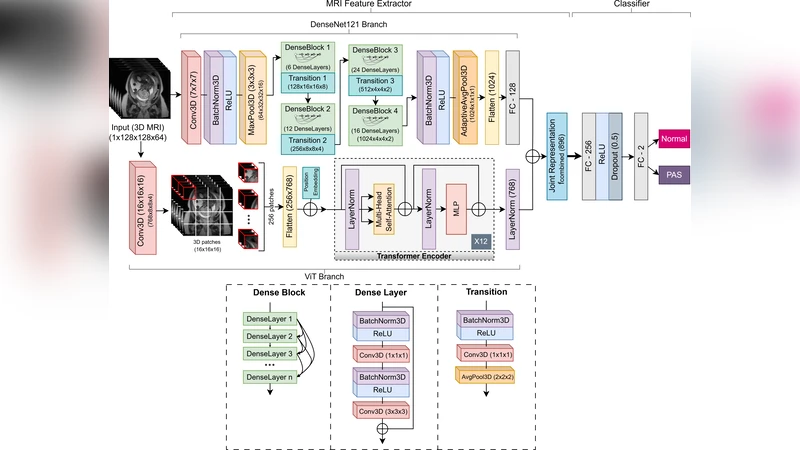
이 논문은 태반착류증(PAS)이라는 고위험 산과 질환의 조기 진단을 목표로, 다중영상 데이터를 통합하는 딥러닝 파이프라인을 체계적으로 설계·검증하였다. 먼저, MRI와 초음파 각각에 최적화된 특징 추출기를 선택하는 과정에서 3D DenseNet121‑Vision Transformer와 2D ResNet50을 비교 실험하였다. 3D DenseNet121은 고해상도 부피 데이터를 효율적으로 처리하면서도 DenseNet의 특성 재사용성을 유지하고, Vision Transformer 모듈을 결합해 전역적인 컨텍스트 정보를 학습한다는 점에서 MRI 영상에 적합했다. 반면, 2D ResNet50은 초음파 이미지의 낮은 해상도와 잡음 특성을 고려했을 때, 깊은 잔차 연결을 통한 안정적인 특징 학습이 가능하였다.
다음으로, 두 모달리티의 특징을 중간 단계에서 결합하는 ‘feature‑level fusion’ 방식을 채택하였다. 이는 각 모달리티가 독립적으로 고차원 표현을 학습한 뒤, 차원 정규화와 가중치 조정을 거쳐 하나의 통합 벡터로 압축되는 구조이다. 이 접근법은 초기 단계에서의 데이터 불균형이나 해상도 차이를 최소화하면서, 서로 다른 물리적 정보를 보완하도록 설계되었다. 또한, 멀티모달 학습 과정에서 교차 엔트로피 손실 외에 모달리티 간 정규화 손실을 추가해 각 특징이 과도하게 지배하지 않도록 균형을 맞추었다.
데이터셋 측면에서는 총 2,436개의 개별 영상( MRI 1,293, 초음파 1,143)과 환자별 매칭된 842쌍의 멀티모달 샘플을 확보하였다. 훈련·검증·테스트를 7:1:2 비율로 분할하고, 테스트 셋은 완전히 독립된 기관에서 수집된 데이터를 사용해 외부 일반화 능력을 검증하였다. 모델 성능 평가는 정확도, AUC, 민감도·특이도, F1‑Score 등 다중 지표를 활용했으며, 멀티모달 모델이 모든 지표에서 단일 모달 모델을 앞섰다. 특히 AUC 0.927은 임상적 의사결정에 충분히 신뢰할 수 있는 수준으로, 기존 초음파 기반 진단의 한계를 크게 보완한다는 점을 강조한다.
한계점으로는 매칭된 MRI‑US 쌍이 전체 데이터의 약 35%에 불과해, 멀티모달 학습 시 데이터 부족 현상이 발생할 가능성이 있다. 또한, 3D DenseNet‑ViT 구조는 연산량이 크고 GPU 메모리 요구사항이 높아 실시간 임상 적용에 제약이 있다. 향후 연구에서는 데이터 증강·생성 모델을 활용한 샘플 확장, 경량화된 트랜스포머 설계, 그리고 전이학습을 통한 소규모 병원 환경 적용 가능성을 탐색할 필요가 있다. 전반적으로 이 연구는 다중영상 딥러닝이 PAS와 같은 복합 질환의 조기 진단에 제공할 수 있는 시너지 효과를 실증적으로 보여주며, 향후 멀티모달 의료 AI의 표준화된 프레임워크 구축에 중요한 발판이 될 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기