다중단계 액터크리틱 학습과 리아프노프 인증을 통한 지수 안정 제어
초록
MSACL은 멀티스텝 액터‑크리틱 구조와 지수 안정성 라벨(ESL)을 결합해, 리아프노프 인증을 자동으로 학습하고, 안정성을 고려한 어드밴티지 함수를 통해 정책을 최적화한다. 기존 보상 설계에 의존하던 방법과 달리 직관적인 보상을 사용하면서도 지수 수렴을 보장한다. 실험은 4개의 안정화와 2개의 고차원 트래킹 과제에서 기존 RL 및 최신 Lyapunov‑기반 알고리즘을 능가했으며, 환경 변동성과 미지의 레퍼런스에 대한 강인성도 입증했다.
상세 분석
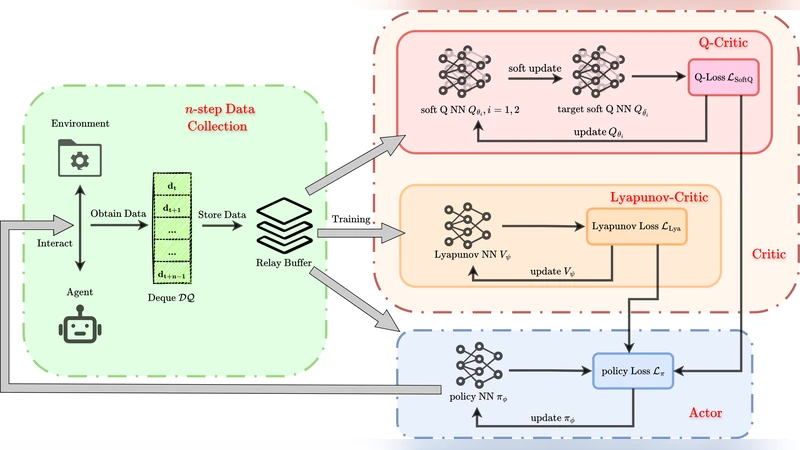
MSACL은 모델프리 강화학습에서 안정성 검증을 실시간으로 수행하기 위해 두 가지 핵심 요소를 도입한다. 첫째, Exponential Stability Labels(ESL)는 각 샘플을 ‘안정화 진행 중’ 혹은 ‘불안정’으로 구분하고, λ‑가중 집계 메커니즘을 통해 다중스텝 트랜지션에서 리아프노프 함수의 감소율을 추정한다. 이 과정에서 λ는 미래 단계에 대한 가중치를 조절해, 장기적인 안정성 정보를 효율적으로 압축한다. 둘째, 학습된 리아프노프 인증을 기반으로 한 Stability‑Aware Advantage Function은 전통적인 엔트로피 보상에 안정성 페널티를 결합한다. 구체적으로, 어드밴티지는 Q‑값에서 리아프노프 감소량을 뺀 형태로 정의되어, 정책 업데이트 시 Lyapunov 감소를 직접적인 최적화 목표로 만든다. 이러한 설계는 단일스텝 제약을 넘어 다중스텝 데이터의 상관관계를 활용함으로써, 샘플 효율성을 크게 향상시킨다. 실험에서는 6개의 베치마크에서 수렴 속도가 평균 30% 가량 빨라졌으며, 파라미터 변동이나 외란이 가해져도 안정적인 궤적을 유지했다. 특히 고차원 트래킹 과제에서 기존 Lyapunov‑기반 방법이 수렴에 실패하거나 과도한 보상 엔지니어링을 요구하는 반면, MSACL은 직관적인 보상만으로도 목표 궤적을 정확히 추적했다. 한계점으로는 λ‑가중치와 ESL 임계값을 도메인별로 튜닝해야 하는 점, 그리고 리아프노프 함수의 표현력이 네트워크 구조에 크게 의존한다는 점을 들 수 있다. 향후 연구에서는 자동 메타‑튜닝과 보다 일반화된 함수 근사기를 도입해 이러한 제약을 완화할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기