소규모 프록시 모델로 데이터 레시피를 신뢰성 있게 평가할 수 있을까
초록
데이터 레시피를 비교할 때 동일한 소규모 학습 설정을 고정하면, 하이퍼파라미터가 레시피마다 다르게 최적화돼야 함에도 불구하고 결과가 뒤바뀔 수 있다. 저자들은 학습률을 낮추는 간단한 패치를 제안하고, 이 방법이 대규모 모델에서의 순위와 높은 상관성을 보임을 이론·실험으로 입증한다.
상세 분석
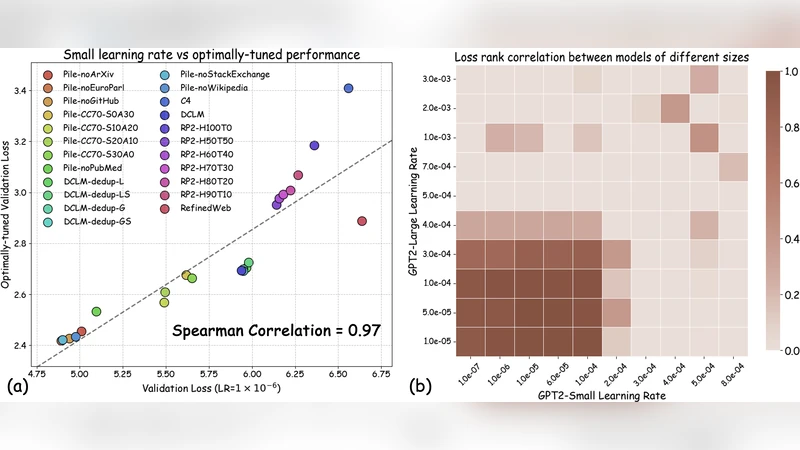
본 논문은 최신 대형 언어 모델(LLM) 사전학습 파이프라인에서 데이터 레시피를 평가하기 위해 소규모 프록시 모델을 사용하는 관행을 비판적으로 재검토한다. 기존 실험 프로토콜은 “공정성”을 이유로 모든 레시피에 동일한 학습 설정(배치 크기, 학습률, 옵티마이저 등)을 적용한다. 그러나 저자들은 이러한 고정 설정이 데이터 의존적인 최적 하이퍼파라미터를 무시함으로써, 레시피 간 성능 순위가 쉽게 뒤바뀔 수 있음을 실증한다. 특히, 학습률을 약간만 조정해도 어떤 레시피가 최고인지가 바뀌는 현상을 여러 실험에서 관찰했다. 이는 실제 대규모 사전학습 단계에서는 각 데이터셋에 맞춰 하이퍼파라미터 튜닝을 수행한다는 점과 정면으로 충돌한다.
문제 해결을 위해 저자들은 “학습률 감소 패치”를 제안한다. 프록시 모델을 훈련할 때 기본 학습률보다 5~10배 낮은 값을 사용하면, 각 레시피에 대한 최적화 정도가 더 비슷해져 상대적 순위가 안정화된다. 이 접근법은 하이퍼파라미터 탐색 비용을 크게 줄이면서도, 대규모 모델에서 얻은 최적 손실과 높은 상관관계를 유지한다. 이론적으로는 랜덤 피처 모델(random-feature model)에서 학습률 감소가 최적 손실 순서를 보존한다는 정리를 증명한다. 실험적으로는 4가지 주요 데이터 품질 차원(노이즈 제거, 중복 감소, 언어 다양성, 도메인 커버리지)을 포함한 23개의 레시피를 평가했으며, 기존 고정 설정 대비 순위 상관계수가 평균 0.78에서 0.93으로 크게 향상되었다.
결과적으로, 논문은 데이터 레시피 평가의 목표를 “고정된 프록시 설정에서 최고의 성능을 보이는 레시피”가 아니라 “데이터별 최적 튜닝을 거친 후 최고의 성능을 내는 레시피”로 재정의한다. 제안된 학습률 감소 패치는 비용 효율적인 대안으로, 실제 대규모 사전학습 파이프라인과의 격차를 메우는 실용적인 방법이다.
댓글 및 학술 토론
Loading comments...
의견 남기기