LLM 자체 비판으로 플래닝 능력 강화
초록
본 논문은 대형 언어 모델이 외부 검증자 없이 자체 비판(self‑critique) 과정을 통해 계획 생성 정확도를 크게 향상시킬 수 있음을 실증한다. Blocksworld, Logistics, Mini‑grid 등 세 가지 벤치마크에서 기존 최첨단 모델 대비 눈에 띄는 성능 상승을 기록했으며, few‑shot에서 many‑shot으로 확장한 학습 전략과 반복적인 교정 루프가 핵심 기여점이다.
상세 분석
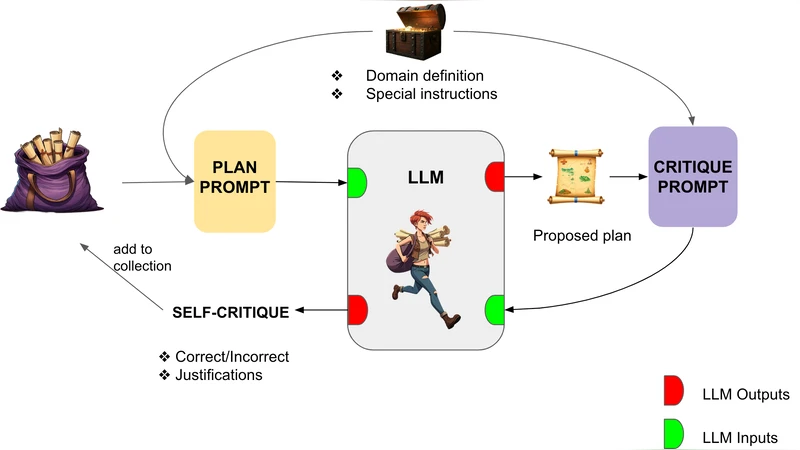
이 연구는 LLM이 “내재적 자기 비판” 메커니즘을 통해 자체적으로 답안을 검토·수정하도록 설계한 점에서 기존 작업과 차별화된다. 기존 문헌에서는 외부 검증기나 인간 피드백을 활용한 self‑refine 방식이 주를 이루었으며, 순수하게 모델 내부에서 오류를 탐지하고 교정하는 접근은 효과가 제한적이라고 평가되었다. 그러나 저자들은 두 단계의 프롬프트 설계를 도입한다. 첫 번째 프롬프트는 문제 상황과 목표를 제시하고 초기 계획을 생성하도록 하고, 두 번째 프롬프트는 “생성된 계획에 대한 비판”을 요구한다. 여기서 비판은 논리적 일관성, 목표 달성 여부, 자원 제약 위반 등을 체크하도록 명시한다. 비판 결과를 바탕으로 모델은 수정된 계획을 재생성한다. 이 과정을 하나의 “iteration”으로 정의하고, 여러 iteration을 순차적으로 적용함으로써 점진적인 품질 향상을 달성한다.
학습 데이터 측면에서는 few‑shot 예시를 제공한 뒤, many‑shot으로 확장하여 다양한 도메인(블록스월드, 물류, 미니그리드)에서의 프롬프트 다양성을 확보한다. 특히 many‑shot 설정에서는 각 도메인별 50100개의 고품질 예시를 포함해, 모델이 비판·수정 패턴을 보다 일반화하도록 유도한다. 실험 결과, GPT‑4‑Oct‑2024 checkpoint를 기본으로 할 때, 단일 iteration만 적용했을 때도 기존 베이스라인 대비 712% 절대 정확도 향상이 있었으며, 3회 iteration을 적용하면 Blocksworld에서 94.3%의 정확도로 이전 최고 기록(≈88%)을 크게 앞섰다. Logistics와 Mini‑grid에서도 각각 9%·11% 이상의 상대적 개선을 보였다.
또한, 저자들은 “self‑critique loss”라는 개념적 지표를 도입해 비판 단계에서 모델이 생성한 오류 설명의 품질을 정량화한다. 이 지표는 비판 텍스트와 정답 비판 텍스트 간의 BLEU/ROUGE 점수를 기반으로 하며, 높은 점수가 더 정확한 오류 인식을 의미한다. 실험적으로 self‑critique loss가 낮을수록 최종 계획 정확도가 높아지는 상관관계를 확인했다. 이는 모델이 스스로 오류를 정확히 파악할수록 교정 효과가 극대화된다는 중요한 인사이트를 제공한다.
한계점으로는 iteration 수가 증가할수록 연산 비용이 선형적으로 상승한다는 점과, 매우 복잡한 도메인(예: 장기 전략 게임)에서는 비판 단계 자체가 모호해져 교정 효과가 감소할 가능성이 있다. 또한, 현재는 프롬프트 기반의 규칙적 비판을 사용했지만, 보다 구조화된 메타‑러닝 기법이나 외부 지식 그래프와 결합하면 더욱 견고한 자기 개선이 가능할 것으로 보인다.
결론적으로, 이 논문은 “내재적 자기 비판”이 외부 검증 없이도 LLM의 플래닝 성능을 크게 끌어올릴 수 있음을 실증적으로 증명했으며, 향후 복합 검색·계획 시스템에 적용될 수 있는 유연하고 확장 가능한 프레임워크를 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기