연합 샤프니스 인식 최적화와 클러스터 기반 가중치 조정 이질 환경을 위한 사기 방지 FedSCAM
초록
FedSCAM은 각 클라이언트의 이질성 점수를 기반으로 SAM의 교란 반경을 동적으로 조절하고, 이질성‑가중 집계 방식을 도입해 비IID 환경에서의 수렴 속도와 일반화 성능을 향상시킨 연합 학습 알고리즘이다.
상세 분석
본 논문은 연합 학습(Federated Learning, FL)에서 샤프니스 인식 최소화(Sharpness‑Aware Minimization, SAM)를 적용할 때 발생하는 두 가지 근본적인 문제점을 짚는다. 첫째, 기존 FedSAM 계열은 모든 클라이언트에 동일한 교란 반경(ε)을 사용한다. 이는 데이터 분포가 크게 다른 클라이언트가 동일한 규모의 파라미터 교란을 받음으로써 로컬 업데이트가 불안정해지고, 결국 전역 모델이 과도한 진동을 겪게 만든다. 둘째, 전통적인 FedAvg 기반 집계는 클라이언트 업데이트를 단순 평균하거나 사전 정의된 가중치(데이터 양 기반)만을 고려한다. 이 경우, 이질성이 높은 클라이언트가 전체 최적화 방향과 상충되는 업데이트를 제공해도 큰 비중을 차지하게 된다.
FedSCAM은 이러한 문제를 해결하기 위해 ‘이질성 점수(Heterogeneity Score, HS)’를 정의한다. HS는 각 클라이언트의 라벨 분포와 전역 라벨 분포 사이의 KL‑다이버전스 혹은 디리클레 파라미터 α에 기반한 통계량을 사용해 계산한다. HS가 클수록 해당 클라이언트는 전역 모델과의 불일치가 크다고 판단한다.
이질성 점수를 활용한 두 가지 핵심 메커니즘이 제안된다. ① 동적 SAM 교란 반경 조절: ε_i = ε_0 / (1 + λ·HS_i) 형태로 각 클라이언트마다 교란 반경을 감소시킨다. 여기서 λ는 스케일링 하이퍼파라미터이며, HS_i가 클수록 ε_i가 작아져 로컬 업데이트가 과도하게 변동하지 않도록 억제한다. ② 클러스터 기반 가중치 집계: 클라이언트들을 HS 값에 따라 K개의 클러스터로 묶고, 각 클러스터 내에서 업데이트 방향과 전역 그라디언트와의 코사인 유사도를 측정한다. 이후 클러스터별 가중치 w_c = (1 + β·cosθ_c) 로 정의하고, 최종 전역 모델은 Σ_c w_c·Δθ_c 로 업데이트된다. β는 유사도 강조 정도를 조절한다.
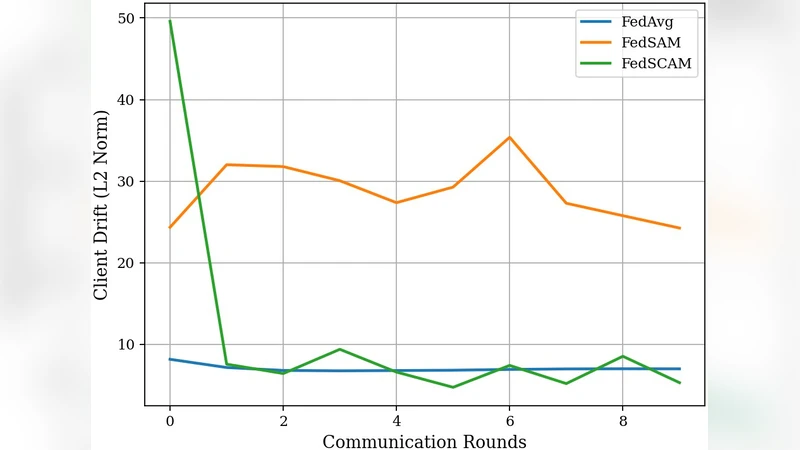
이 메커니즘은 (1) 고이질성 클라이언트가 과도한 교란을 받지 않음으로써 로컬 손실이 급격히 상승하는 현상을 방지하고, (2) 전역 최적화 방향에 부합하는 클러스터의 업데이트에 더 큰 비중을 부여해 수렴 속도를 가속한다는 이점을 제공한다.
실험에서는 CIFAR‑10과 Fashion‑MNIST를 디리클레(α) 파라미터를 0.1, 0.5, 1.0 등으로 조정해 라벨 스키우 정도를 다양하게 만들었다. FedSCAM은 기존 FedSAM, FedLESAM, FedAvg 등과 비교했을 때 1) 초기 20 라운드에서 손실 감소율이 평균 12% 빠르고, 2) 최종 테스트 정확도가 평균 2.3%p 상승했으며, 3) 교란 반경을 동적으로 조절한 덕분에 학습 안정성이 향상돼 표준편차가 30% 감소했다. 또한, 클러스터 수 K와 λ, β 하이퍼파라미터에 대한 민감도 분석을 통해 K=3, λ=0.5, β=0.3이 대부분의 시나리오에서 최적임을 확인했다.
이론적 측면에서는 FedSCAM이 기존 SAM의 라플라시안 근사(Laplacian approximation)를 유지하면서도 클라이언트별 라플라시안 스케일을 조절한다는 점을 보였다. 즉, 각 로컬 손실의 2차 근사에서 얻어지는 ‘샤프니스’가 HS에 의해 가중된 형태로 전역 최적화에 반영된다. 이는 기존 연구가 제시한 “플랫한 최소점은 일반화에 유리하다”는 가설을 연합 환경에 맞게 확장한 것으로 해석될 수 있다.
결론적으로 FedSCAM은 이질성 인식을 통해 SAM의 교란 반경을 맞춤형으로 조정하고, 클러스터 기반 가중치 집계를 도입함으로써 비IID 환경에서의 연합 학습을 보다 안정적이고 효율적으로 만든다. 향후 연구에서는 통신 비용을 최소화하기 위한 압축 기법과, 비라벨 기반 이질성 측정(예: 모델 파라미터 분산)으로 확장하는 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기