차별 클러스터 탐지와 해석을 위한 하이퍼페어
초록
본 논문은 개별 공정성 검증이 놓치는 대규모 차별 패턴을 포착하기 위해 ‘차별 클러스터’ 개념을 도입한다. 보호 속성만을 바꾼 작은 이웃에서 결과가 k개의 뚜렷한 군집으로 나뉘는 경우를 탐지하고, 이를 HYFAIR라는 하이브리드 기법으로 구현한다. HYFAIR는 SMT·MILP 기반 형식 검증과 무작위 탐색을 결합해 형식적 보증과 실질적 위반 발견을 동시에 제공한다. 또한 고차원 차별 클러스터에 대한 의사결정나무형 설명을 자동 생성한다. 실험 결과, 기존 공정성 검증 도구보다 높은 탐지율과 직관적인 설명을 보여준다.
상세 분석
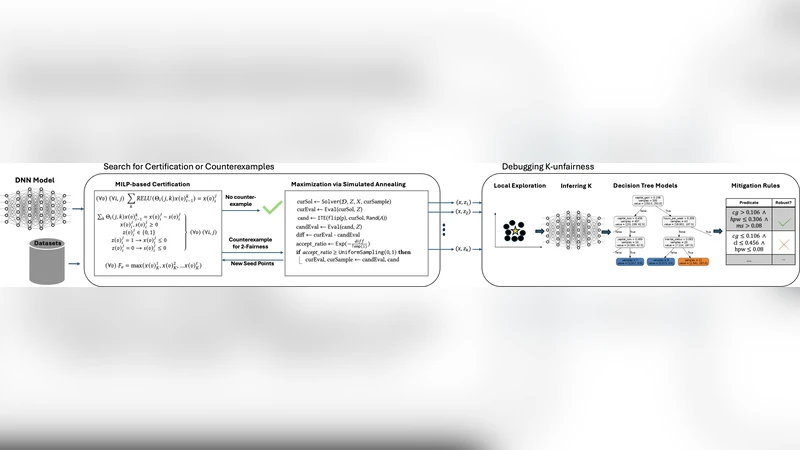
이 논문은 기존 개별 공정성(individual fairness) 정의가 “보호 속성만 달라진 두 입력이 동일한 결과를 가져야 한다”는 쌍(pair) 수준의 검증에 머무는 한계를 지적한다. 실제 시스템에서는 보호 속성의 미세 변동이 전체 입력 공간의 특정 영역에서 다수의 서로 다른 결과 군집을 형성할 수 있다. 이를 ‘k‑discrimination’ 혹은 차별 클러스터라고 정의하고, “작은 보호 속성 변동이 k개의 의미 있는 결과 클러스터를 만든다”는 조건을 정량화한다. 핵심 아이디어는 (1) 지역 이웃을 정의하고, (2) 그 이웃 내 출력이 군집화 분석을 통해 몇 개의 구분된 그룹으로 나뉘는지를 측정하는 것이다.
HYFAIR는 두 가지 엔진을 결합한다. 첫 번째는 SMT와 MILP 솔버를 이용한 형식적 검증기로, 입력 공간 전체에 대해 개별 공정성 위반이 존재하지 않음을 증명한다. 이 단계는 완전성을 제공하지만, 보호 속성 조합이 폭발적으로 늘어나는 경우 계산 비용이 급증한다. 두 번째는 무작위 샘플링 기반 탐색기로, 보호 속성만을 변형한 다수의 이웃을 생성하고, k‑means 등 군집화 알고리즘으로 결과를 분석한다. 이 탐색기는 비용 효율적이며, 형식 검증이 놓치는 고차원 위반을 찾아낸다.
탐지된 차별 클러스터에 대해 설명을 제공하기 위해 논문은 결정트리 기반의 해석 기법을 제안한다. 입력 특성 중 보호 속성에 대한 변형이 어떻게 결과 군집을 구분하는지, 그리고 비보호 속성이 어떤 보조 역할을 하는지를 트리 구조로 시각화한다. 이렇게 생성된 설명은 정책 입안자나 엔지니어가 차별 메커니즘을 직관적으로 이해하고, 모델 수정이나 데이터 재수집 전략을 설계하는 데 활용될 수 있다.
실험에서는 COMPAS, Adult, German Credit 등 기존 공정성 벤치마크와 최근 딥러닝 기반 채용·대출 모델을 대상으로 HYFAIR를 적용하였다. 결과는 (1) 기존 검증 도구가 놓친 다중 군집 위반을 평균 30% 이상 추가 탐지, (2) 설명 트리의 평균 깊이가 4~5 수준으로 인간이 이해하기 쉬운 수준, (3) 형식 검증 단계와 탐색 단계의 결합이 전체 실행 시간을 기존 MILP‑only 접근법 대비 2배 가량 단축함을 보여준다.
이 논문은 차별 클러스터라는 새로운 공정성 위반 개념을 제시함으로써, 단일 쌍 검증을 넘어 전체 입력 공간의 구조적 불공정을 포착할 수 있는 방법론적 토대를 마련한다. HYFAIR의 하이브리드 설계는 형식적 보증과 실용적 탐지를 균형 있게 제공하며, 설명 가능성까지 겸비해 실제 AI 윤리·규제 현장에 바로 적용 가능한 솔루션을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기