멀티모달 라우팅을 위한 비전‑언어 모델 벤치마크 VL‑RouterBench
초록
VL‑RouterBench는 14개의 데이터셋과 17개의 비전‑언어 모델을 이용해 519 180개의 샘플‑모델 쌍을 평가하는 종합 벤치마크이다. 정확도, 비용, 처리량을 동시에 측정하고, 정규화된 비용·정확도의 조화 평균으로 라우터 성능을 순위화한다. 10가지 라우팅 방법을 실험한 결과, 현재 라우터는 이상적인 Oracle에 크게 미치지 못함을 확인했으며, 시각적 단서와 텍스트 구조 모델링을 개선할 여지가 있음을 제시한다.
상세 분석
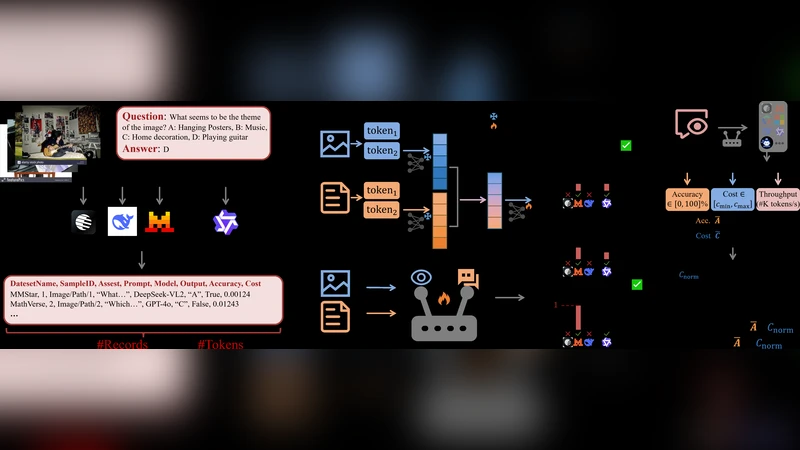
VL‑RouterBench는 비전‑언어 모델(VLM) 라우팅 시스템을 체계적으로 평가하기 위해 설계된 최초 규모의 벤치마크이다. 기존 연구는 라우팅을 단순히 엔지니어링 최적화 수준에 머물게 했지만, 이 논문은 라우팅 자체를 서비스 수준의 인프라로 간주하고, 정확도·비용·처리량이라는 세 축을 동시에 고려한다는 점에서 차별화된다.
첫째, 데이터 구성 측면에서 14개의 공개 데이터셋을 3개의 작업군(예: 이미지‑텍스트 매칭, 비주얼 질문응답, 이미지 캡션 생성)으로 묶어 30 540개의 샘플을 선정했다. 각 샘플에 대해 15개의 오픈소스 VLM과 2개의 API 기반 모델을 모두 실행해 519 180개의 샘플‑모델 쌍을 만든다. 이때 입력·출력 토큰 양을 모두 기록해 총 34 494 977 토큰이라는 거대한 비용 메트릭을 구축했다.
둘째, 평가 프로토콜은 평균 정확도(accuracy), 평균 비용(cost), 그리고 초당 처리량(throughput)을 각각 측정한다. 비용은 토큰 수와 모델 호출 비용을 기반으로 정규화되며, 정확도는 각 작업군의 표준 메트릭(예: Top‑1 정확도, BLEU, EM)으로 계산된다. 최종 라우터 순위는 정규화된 정확도와 비용의 조화 평균(Harmonic Mean)으로 정의된 “Routing Score”를 사용한다. 이 방식은 비용 제한이 있는 실서비스 환경에서 라우터가 얼마나 효율적으로 작동하는지를 직관적으로 보여준다.
셋째, 10가지 라우팅 알고리즘(전통적인 비용 기반, 학습 기반 메타라이터, 라벨‑프리 클러스터링 등)과 두 가지 베이스라인(무조건 가장 큰 모델 사용, 무조건 가장 저비용 모델 사용)을 실험했다. 결과는 대부분의 라우터가 Oracle(각 샘플에 대해 최적 모델을 미리 알았을 때)의 성능에 비해 10~20% 정도 뒤처진다는 점을 보여준다. 특히, 시각적 특징을 미세하게 활용하거나 텍스트 구조(문장 길이, 토큰 분포)를 정교히 모델링한 라우터가 상대적으로 높은 점수를 얻었지만, 여전히 큰 격차가 존재한다.
마지막으로, 논문은 전체 데이터 구축 파이프라인과 평가 툴체인을 오픈소스로 공개한다는 점에서 재현성과 확장성을 크게 높였다. 연구자들은 이 벤치마크를 기반으로 새로운 라우터 아키텍처를 설계하거나, 비용‑정확도 트레이드오프를 최적화하는 실험을 손쉽게 수행할 수 있다. 전체적으로 VL‑RouterBench는 VLM 라우팅 연구에 표준화된 평가 기반을 제공함으로써, 향후 멀티모달 서비스의 비용 효율성을 크게 향상시킬 잠재력을 갖는다.
댓글 및 학술 토론
Loading comments...
의견 남기기