AI 기반 커널 자동 생성 멀티에이전트 프레임워크
초록
AKG kernel agent는 최신 AI 모델에 필요한 고성능 연산 커널을 자동으로 생성·이식·튜닝하는 멀티에이전트 시스템이다. Triton, TileLang, C++, CUDA‑C 등 다양한 DSL을 지원해 GPU와 NPU 등 여러 하드웨어 백엔드에 맞는 코드를 생산한다. KernelBench 평가에서 Triton 기반 구현이 PyTorch Eager 대비 평균 1.46배 빠른 성능을 보이며, DSL 확장성과 하드웨어 적응성이 뛰어남을 입증한다.
상세 분석
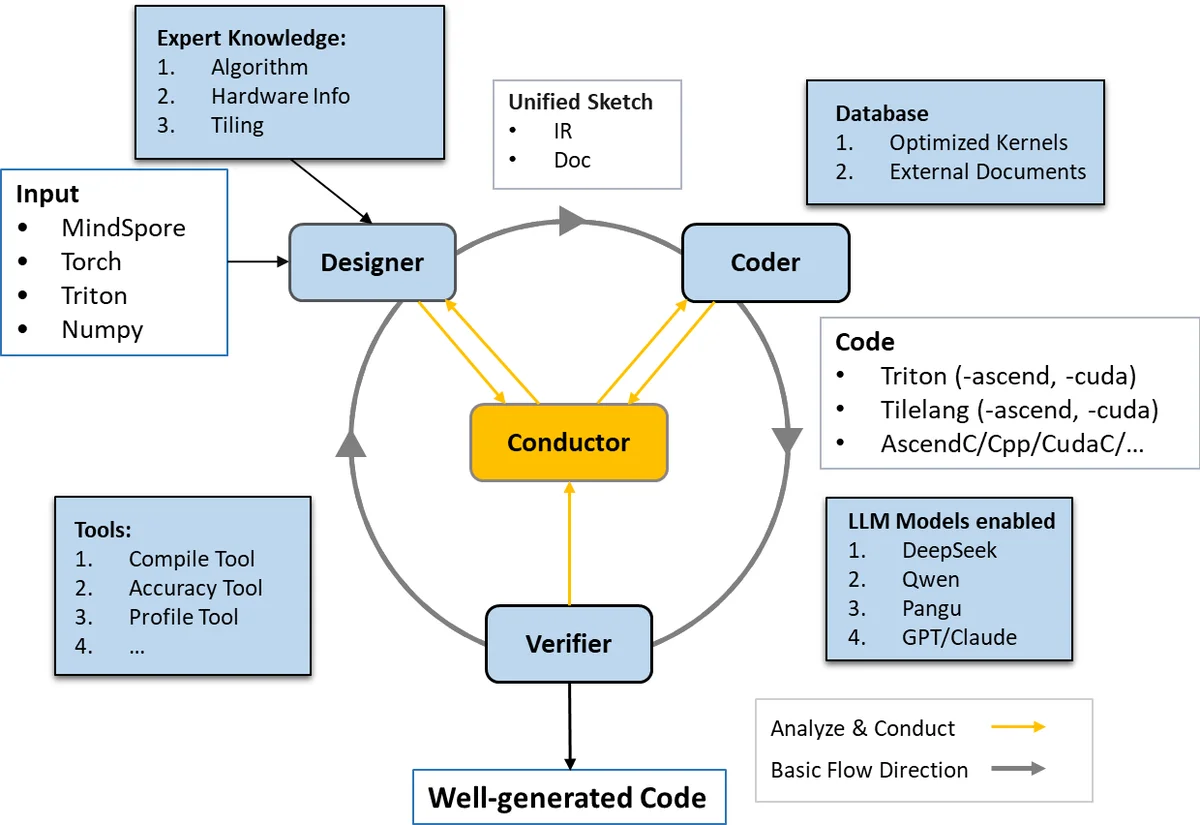
본 논문은 AI 모델의 급격한 규모 확대와 하드웨어 다양화가 초래한 커널 최적화 병목을 해결하기 위해, LLM 기반 코드 생성 기술을 활용한 자동화 프레임워크를 제안한다. 핵심 아이디어는 ‘에이전트’라는 독립적인 모듈을 여러 개 배치해 각각 DSL 파싱, 하드웨어 특성 추출, 성능 모델링, 코드 생성·검증·튜닝을 담당하게 함으로써, 복합적인 최적화 과정을 파이프라인 형태로 구성하는 것이다.
첫 번째 에이전트는 사용자가 정의한 연산 사양을 받아 DSL‑중립적인 추상 표현(AST)으로 변환한다. 여기서는 트리 구조의 연산 그래프와 메모리 접근 패턴을 명시적으로 기록해, 이후 단계에서 하드웨어 특화 정보를 결합하기 쉽도록 설계했다. 두 번째 에이전트는 목표 하드웨어의 메모리 계층, 연산 유닛 수, 레지스터 파일 크기 등을 메타데이터 형태로 제공받아, 추상 표현에 맞는 최적화 전략(예: 스레드 블록 크기, 워프 스케줄링, 텐서 코어 활용)을 제안한다.
세 번째 에이전트는 LLM(대규모 언어 모델)을 프롬프트 엔진으로 활용해, 제안된 전략을 기반으로 선택된 DSL(Triton, TileLang, CUDA‑C 등)으로 실제 커널 코드를 생성한다. 이때 모델은 기존 최적화 사례와 벤치마크 데이터를 학습한 파라미터를 사용해, 반복문 전개, 메모리 프리패칭, 벡터화 등 세부 최적화를 자동 삽입한다.
생성된 코드는 네 번째 에이전트에 의해 자동 컴파일·실행 테스트를 거치며, 성능 프로파일링 결과를 피드백으로 받아 파라미터(스레드 수, 블록 크기 등)를 미세 조정한다. 이 과정은 베이지안 최적화와 강화학습 기반 탐색을 결합해, 제한된 탐색 횟수 내에 최적에 근접한 설정을 찾아낸다.
마지막으로, 검증 에이전트는 수치 정확도와 메모리 안전성을 검사한다. 정밀도 손실이 허용되는 경우(예: 양자화)에는 자동으로 허용 오차 범위를 조정하고, 그렇지 않은 경우에는 재생성 루프를 트리거한다. 전체 시스템은 모듈형 설계 덕분에 새로운 DSL이나 하드웨어 백엔드를 플러그인 형태로 손쉽게 추가할 수 있다.
실험 결과는 Triton DSL을 사용해 GPU와 NPU 백엔드에 적용했을 때, 기존 PyTorch Eager 구현 대비 평균 1.46배의 속도 향상을 보였으며, 특히 메모리 바운드 연산에서 더 큰 이득을 얻었다. 이는 자동 튜닝이 인간 전문가 수준의 파라미터 선택을 능가함을 의미한다. 또한, 코드 라인 수가 평균 30% 감소해 유지보수 비용도 낮아졌다.
이러한 설계는 향후 AI 시스템이 새로운 하드웨어와 연산 패턴에 빠르게 적응하도록 하는 핵심 인프라가 될 가능성을 시사한다. 다만, LLM 기반 코드 생성의 신뢰성 확보와 대규모 하드웨어 스펙 변동에 대한 지속적인 메타데이터 업데이트가 필요하다는 한계점도 언급된다.