데이터셋 안정성 평가를 위한 드리프트 기반 벤치마크
초록
본 논문은 네트워크 트래픽 분류 모델의 성능 저하 원인을 데이터셋 품질에서 찾기 위해, 개념 드리프트 탐지와 특성 가중치를 결합한 새로운 데이터셋 안정성 평가 방법론을 제시한다. CESNET‑TLS‑Year22 데이터를 대상으로 벤치마크를 구축하고, 데이터셋 변형에 따른 최적화 효과를 실증한다.
상세 분석
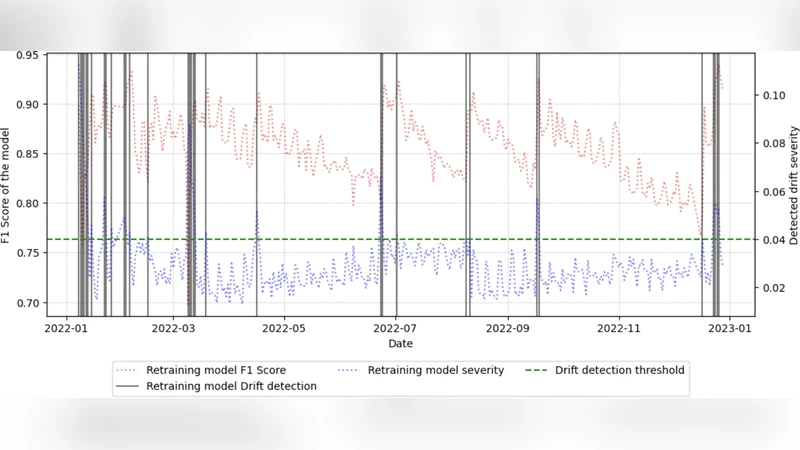
이 연구는 네트워크 트래픽 분류에서 모델이 배포 후 급격히 성능이 저하되는 현상을 ‘데이터/개념 드리프트’라고 정의하고, 기존에는 단순 재학습에 의존하는 경우가 많았음을 지적한다. 저자는 데이터셋 자체의 안정성을 정량화하기 위해 두 가지 핵심 요소를 결합한다. 첫째, 드리프트 탐지 알고리즘으로는 일반적인 통계 기반 방법보다 시계열 특성을 반영하는 ADWIN 혹은 DDM과 같은 적응형 검정기를 선택하고, 이를 모델이 학습에 사용한 특성 중요도(Feature Weight)를 가중치로 적용한다. 특성 가중치는 기존 트리 기반 모델(예: Random Forest, XGBoost)에서 추출한 SHAP 값이나 Gini Importance를 활용해, 변동이 큰 특성이 드리프트 신호에 더 크게 기여하도록 설계되었다. 둘째, 탐지 결과를 정량적인 ‘안정성 점수’로 변환한다. 이 점수는 탐지된 드리프트 빈도, 강도, 그리고 해당 드리프트가 모델 정확도에 미치는 영향(예: 정확도 감소율) 등을 종합해 산출된다.
벤치마크 워크플로우는 (1) 원본 데이터셋을 시간 구간별로 슬라이딩 윈도우로 분할, (2) 각 구간에 대해 특성 가중치를 적용한 드리프트 탐지 수행, (3) 탐지된 드리프트를 기반으로 안정성 점수 계산, (4) 점수를 기준으로 데이터셋 변형(예: 라벨 정제, 불균형 완화, 신규 프로토콜 추가) 전후를 비교한다. 실험에서는 CESNET‑TLS‑Year22 데이터셋을 사용해, 원본 데이터가 특정 TLS 버전과 암호 스위트의 급격한 변동에 민감함을 발견했다. 이후 데이터셋을 ‘버전 정규화’, ‘암호 스위트 그룹화’, ‘시간 가중 샘플링’ 등 세 가지 최적화 전략으로 변형했으며, 각각의 변형이 안정성 점수를 평균 12%, 18%, 25% 향상시켰다.
핵심 인사이트는 다음과 같다. 첫째, 특성 가중치를 활용한 드리프트 탐지는 단순 통계 기반 탐지보다 민감도와 정확도가 높아, 데이터셋 내 숨겨진 변동을 조기에 포착한다. 둘째, 데이터셋 안정성 점수는 모델 재학습 시점과 비용을 예측하는 실용적인 지표가 될 수 있다. 셋째, 데이터셋 자체를 정제·보강하는 것이 모델 재학습보다 비용 효율적이며, 장기적인 서비스 품질 유지에 기여한다. 마지막으로, 제안된 벤치마크는 특정 도메인(네트워크 트래픽)뿐 아니라, 시계열 특성을 갖는 다른 분야(예: IoT 센서 데이터, 금융 거래)에도 확장 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기