데이터는 충분한가 저차원 구조에서 본 생성·비전‑언어 모델의 균일 수렴 한계
초록
본 논문은 생성 모델과 비전‑언어 모델(VLM)이 저차원 의미 임베딩에 대해 매끄럽게 변할 때, 제한된 샘플 수만으로도 정확도와 캘리브레이션을 입력 전반에 걸쳐 균일하게 보장할 수 있음을 이론적으로 입증한다. 핵심은 모델 출력이 프롬프트 임베딩에 대해 Lipschitz 연속성을 갖는다는 가정 하에, 임베딩 공간의 내재 차원과 고유값 감쇠율에 기반한 비대칭적(Uniform) 수렴 경계와 샘플 복잡도 식을 도출한 것이다. 이를 통해 파라미터 수와 무관하게 데이터가 충분한 조건을 정량화하고, 특히 의료·생명과학 분야에서 희귀 질환이나 소수 집단에 대한 최악‑사례 오류를 사전에 진단할 수 있는 지표를 제공한다.
상세 분석
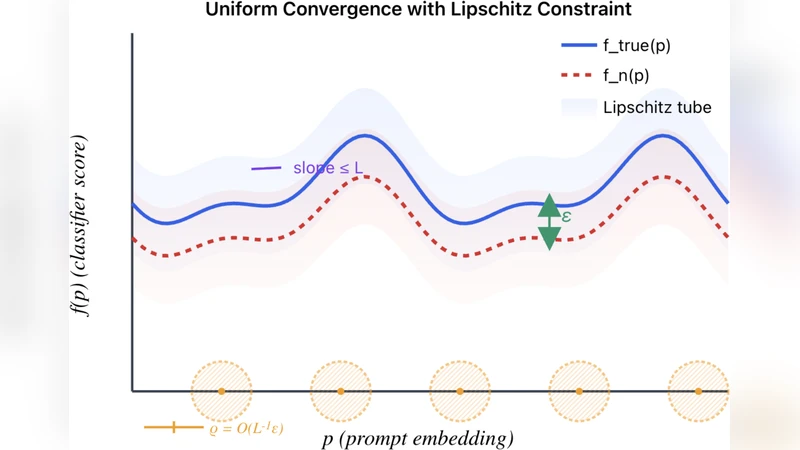
본 연구는 현대의 대규모 생성·비전‑언어 모델이 실제 의료·과학 현장에서 사용될 때, 평균적인 성능 지표만으로는 충분히 신뢰할 수 없다는 점을 출발점으로 삼는다. 특히 “uniform convergence”라는 개념을 도입해, 모든 입력·클래스·서브팝ulation에 대해 동일한 오류 한계를 확보하는 것이 목표이다. 이를 위해 저차원 구조 가정을 두었다. 구체적으로, 모델이 텍스트 프롬프트 혹은 이미지‑텍스트 결합 임베딩을 입력받아 출력 확률을 생성하는 과정이, 고차원 파라미터 공간이 아니라 상대적으로 낮은 차원의 의미 임베딩 공간에서 매끄럽게 변한다고 가정한다. 이 가정은 최근 연구에서 관찰된 임베딩 스펙트럼의 급격한 고유값 감소와, 주성분 몇 개만으로 대부분의 변동을 설명할 수 있다는 사실에 근거한다.
가정 하에, 저자는 먼저 Lipschitz 연속성을 수학적으로 정의한다. 즉, 두 프롬프트 임베딩 𝑧₁, 𝑧₂에 대해 모델 출력 확률 𝑓(·|𝑧)가 ‖𝑓(·|𝑧₁)−𝑓(·|𝑧₂)‖₁ ≤ L·‖𝑧₁−𝑧₂‖₂ 를 만족한다는 것이다. 이 조건은 임베딩 변화가 작을 때 출력도 제한된 범위 내에서만 변한다는 의미이며, 실제 대형 언어·비전 모델에서 실험적으로 확인된 “smoothness”와 일치한다.
그 다음, 저자는 Rademacher 복잡도와 covering number 개념을 이용해, 임베딩 공간의 유효 차원 d_eff (예: 고유값이 λ₁≥…≥λ_d 에서 Σ_{i>k} λ_i / Σ_{i≤k} λ_i ≤ ε 인 최소 k) 를 기반으로 uniform convergence 경계를 도출한다. 핵심 정리는 다음과 같다. n개의 i.i.d. 샘플이 주어졌을 때, 확률 1−δ 로 모든 임베딩 z∈𝒵에 대해
|𝔼
댓글 및 학술 토론
Loading comments...
의견 남기기