데이터 투명성 등급제 생성형 AI 데이터셋을 위한 준수 평가 프레임워크
초록
본 논문은 생성형 AI 모델 학습에 사용되는 대규모 데이터셋의 투명성·책임성·보안성을 평가하기 위한 Compliance Rating Scheme(CRS)을 제안한다. 데이터 출처 추적과 합법성 검증을 자동화하는 파이썬 라이브러리를 공개하여, 기존 파이프라인에 손쉽게 통합하고, 새로운 데이터 수집 과정에서도 사전 준수를 지원한다.
상세 분석
CRS는 데이터셋의 “투명성(Transparency)·책임성(Accountability)·보안(Security)”이라는 세 축을 핵심 원칙으로 정의하고, 각각을 정량화 가능한 메트릭으로 세분화한다. 투명성은 원본 출처, 라이선스 명시, 수집 시점·방법 등을 메타데이터 형태로 기록하도록 요구한다. 책임성은 데이터 제공자와 재사용자 간의 계약적 의무, 데이터 정제 과정에서 발생한 오류 로그, 그리고 데이터 변경 이력(버전 관리)을 포함한다. 보안은 개인식별정보(PII) 탈락, 저작권 침해 위험 평가, 악성 콘텐츠 탐지 등을 자동화된 검사 도구와 연동한다.
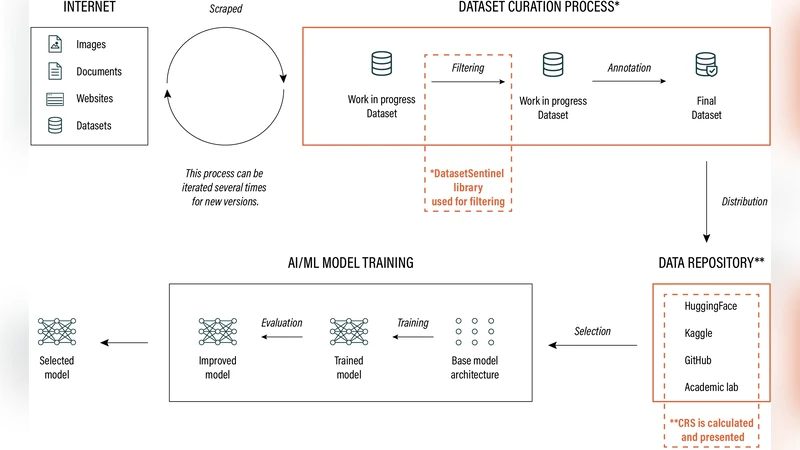
제안된 파이썬 라이브러리는 데이터 프로비넌스 기술을 기반으로 하여, 데이터 파일에 블록체인‑유사 해시 체인을 삽입하고, 메타데이터를 JSON‑LD 형태로 캡슐화한다. 이를 통해 데이터셋이 복제·편집·재배포될 때마다 무결성 검증이 가능하고, 원본 출처를 역추적할 수 있다. 라이브러리는 두 가지 모드로 동작한다. ① Reactive Mode에서는 기존 데이터셋을 스캔해 CRS 점수를 산출하고, 미비 항목에 대한 상세 리포트를 제공한다. ② Proactive Mode에서는 웹 크롤러와 연동해 실시간으로 수집 대상 웹 페이지의 저작권 표시·robots.txt·데이터 사용 정책 등을 파싱하고, 위반 가능성이 감지되면 자동으로 수집을 차단하거나 경고한다.
실험에서는 공개된 LAION‑5B, Common Crawl, 그리고 한국어 위키데이터 등 3개의 대규모 데이터셋에 CRS를 적용하였다. 결과적으로 LAION‑5B는 라이선스 표기가 불완전하고, PII 검출 비율이 2.3%에 머물러 낮은 보안 점수를 받았다. 반면 Common Crawl은 버전 관리와 변경 로그가 부재해 책임성 점수가 낮았으며, 한국어 위키데이터는 메타데이터가 풍부해 전반적으로 높은 점수를 획득했다. 이러한 정량적 평가를 통해 연구자와 기업이 데이터셋 선택 시 위험 요소를 명확히 인식하고, 보완 작업을 우선순위화할 수 있음을 입증한다.
또한, CRS는 법적·윤리적 규제와 연계될 수 있도록 설계되었다. 예를 들어 EU AI Act의 고위험 데이터 요구사항과 미국의 AI 책임법 초안에 명시된 “데이터 출처 투명성” 조항을 메트릭으로 매핑한다. 따라서 CRS 점수는 단순 기술적 지표를 넘어 규제 준수 여부를 판단하는 근거 자료로 활용 가능하다.
마지막으로, 오픈소스 커뮤니티와의 협업을 강조한다. 라이브러리 코드는 MIT 라이선스로 공개되었으며, 플러그인 구조를 채택해 사용자가 자체 검증 로직(예: 도메인‑특화 PII 탐지기)을 손쉽게 추가할 수 있다. 향후에는 자동화된 법적 자문 API와 연동해 실시간 규제 업데이트를 반영하고, 데이터셋 인증 마크(Compliance Badge)를 발급하는 생태계 구축을 목표로 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기