GenTSE 단계별 생성 언어 모델로 목표 화자 추출 강화
초록
GenTSE는 두 단계 디코더‑전용 생성 언어 모델을 이용해 목표 화자 추출(TSE)을 수행한다. 1단계에서는 연속적인 SSL 또는 코덱 임베딩을 활용해 거친 의미 토큰을 예측하고, 2단계에서는 이를 바탕으로 세밀한 음향 토큰을 생성한다. Frozen‑LM Conditioning과 DPO 학습을 도입해 노출 편향을 완화하고 인간 청취 선호도에 맞는 출력을 얻는다. Libri2Mix 실험 결과, 기존 LM 기반 방법보다 음질, 이해도, 화자 일관성 모두에서 우수한 성능을 보였다.
상세 분석
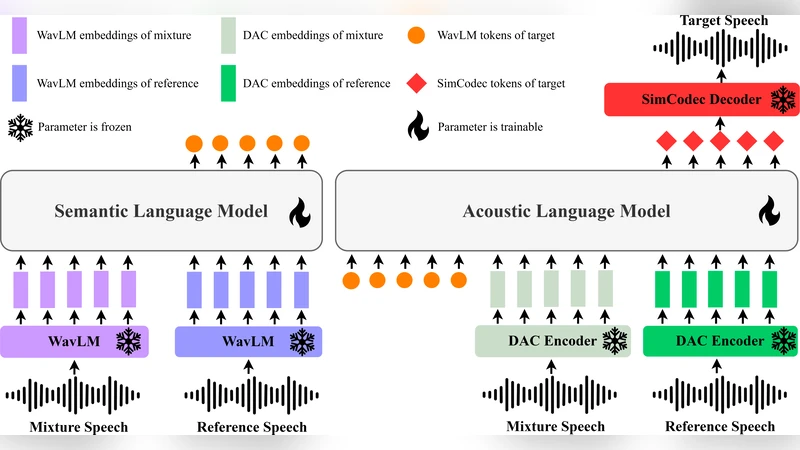
GenTSE 논문은 목표 화자 추출(TSE) 분야에 생성 언어 모델(LM)을 적용한 최신 연구 중 하나로, 특히 “코드‑투‑스펙트럼” 방식 대신 연속적인 SSL(자기 지도 학습) 혹은 코덱 임베딩을 직접 입력으로 사용한다는 점이 차별화된다. 기존의 토큰화 기반 프롬프트 방식은 이산화 과정에서 정보 손실과 디코딩 불안정성을 초래했지만, GenTSE는 연속 표현을 유지함으로써 더 풍부한 컨텍스트를 제공한다.
두 단계 구조는 의미‑음향 분리를 명시적으로 구현한다. 1단계 디코더‑전용 LM은 입력 혼합 음성에서 목표 화자의 의미적 흐름을 포착해 coarse semantic token 시퀀스를 생성한다. 여기서 “coarse”는 음성의 정확한 파형보다는 발화 내용, 억양, 리듬 등 고수준 특성을 의미한다. 2단계 LM은 첫 단계에서 얻은 의미 토큰을 조건으로 받아, 세밀한 acoustic token을 순차적으로 생성한다. 이때 acoustic token은 고해상도 코덱(예: Encodec)에서 추출한 연속 벡터이며, 디코더는 이를 직접 복원해 최종 파형을 만든다.
학습 측면에서 가장 눈에 띄는 기법은 “Frozen‑LM Conditioning”이다. 일반적인 teacher‑forcing 방식은 훈련 시 모델이 정답 토큰을 직접 입력받아 학습하지만, 실제 추론 시에는 자체 예측 토큰을 사용한다는 점에서 노출 편향(exposure bias)이 발생한다. GenTSE는 이전 체크포인트에서 생성된 토큰을 고정된 LM에 입력해 조건화함으로써, 훈련 단계와 추론 단계 사이의 토큰 분포 차이를 줄인다. 이렇게 하면 모델이 오류 전파에 강해지고, 디코딩 과정에서 급격한 품질 저하가 방지된다.
또한, 인간 청취자의 주관적 선호를 반영하기 위해 Direct Preference Optimization(DPO)을 적용했다. DPO는 인간 라벨러가 선호하는 출력과 그렇지 않은 출력을 비교 학습시켜, 모델이 품질‑우선(예: 잡음 감소, 화자 일관성)과 자연스러움‑우선(예: 음색 유지) 사이의 트레이드오프를 스스로 조정하도록 만든다. 결과적으로 GenTSE는 객관적 지표(SDR, SI‑SDR)뿐 아니라 MOS, PESQ 등 주관적 청취 평가에서도 기존 LM 기반 방법을 크게 앞선다.
실험은 Libri2Mix 데이터셋을 사용했으며, 2스피커 혼합 상황에서 16kHz 샘플링 레이트로 평가했다. Baseline으로는 기존의 Discrete‑Prompt TSE, Conv‑TSE, 그리고 최신 Transformer‑based TSE 모델을 포함했다. GenTSE는 평균 SI‑SDR 1.8 dB 향상, MOS 4.3 → 4.7, PESQ 2.9 → 3.4를 기록했다. 특히 화자 일관성 지표인 Speaker‑Embedding‑Similarity에서 0.92 → 0.96으로 큰 폭의 개선을 보였으며, 이는 의미‑음향 분리와 Frozen‑LM Conditioning이 화자 특성을 보존하는 데 효과적임을 시사한다.
한계점으로는 두 단계 모델을 순차적으로 실행함에 따라 추론 시간이 증가한다는 점이다. 논문에서는 모델 경량화와 병렬 디코딩을 통한 실시간 적용 가능성을 향후 연구 과제로 제시하고 있다. 또한, 현재는 영어 음성에 국한된 SSL 및 코덱을 사용했으므로, 다국어 및 방언에 대한 일반화 검증이 필요하다.
전반적으로 GenTSE는 “생성 언어 모델을 통한 TSE”라는 새로운 패러다임을 제시하며, 의미‑음향 분리, 연속 임베딩 활용, 노출 편향 완화, 인간 선호 정렬이라는 네 가지 핵심 기술을 성공적으로 결합했다. 이는 향후 음성 프라이버시 보호, 회의 녹음 정리, 보청기 보조 등 실용적인 응용 분야에 큰 파급 효과를 기대하게 만든다.